





 CLOUD
CLOUD
CLOUD
CLOUD
CLOUD
Graphics processing units are becoming increasingly popular in the data center to accelerate data-intensive workloads such as machine learning and deep learning. Now, Nvidia Corp., the world’s largest maker of GPUs, is pushing another use case, pairing them with Kubernetes clusters as way to accelerate training for deep-learning models.
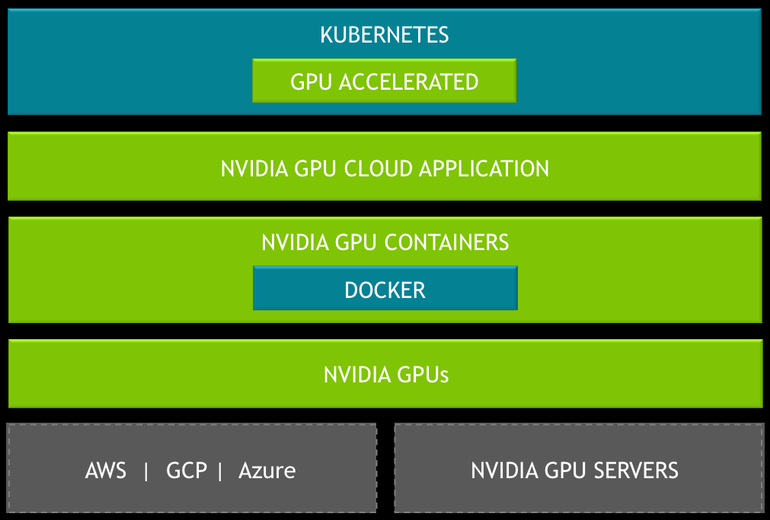
The company on Tuesday said it’s making its release candidate for Kubernetes on Nvidia GPUs available for free to developers. It’s aimed at enterprises that are training deep learning models on multicloud GPU clusters, the company said.
Kubernetes on Nvidia GPUs was announced during the Computer Vision and Pattern Recognition conference, where it also unveiled a new version of its inference optimizer tool and runtime engine TensorRT. Nvidia also launched a GPU data augmentation and image loading library named DALI, which is designed to optimize data pipelines for deep-learning frameworks.
Nvidia said the idea behind its Kubernetes on GPUs push is to make the software container orchestration platform more “GPU-aware.” Kubernetes on Nvidia GPUs is aimed at containers running artificial intelligence applications, and will help developers to better orchestrate resources on GPU clusters spread across multiple cloud hosts, it said.
“This is big as Kubernetes-hosted applications can now access the performance of a GPU,” said Patrick Moorhead, founder and principal analyst at Moor Insights & Strategy. “This enables much higher-level scalability than before on virtual machines.”
Nvidia’s announcement comes just weeks after Google LLC. launched a beta version of GPUs on its Kubernetes Engine platform, in a move it said was designed to accelerate image processing and machine learning workloads. At the time, Google said its cloud GPUs could be used to create Kubernetes node pools powered by Nvidia’s Tesla V100, P100 and K80 processors.
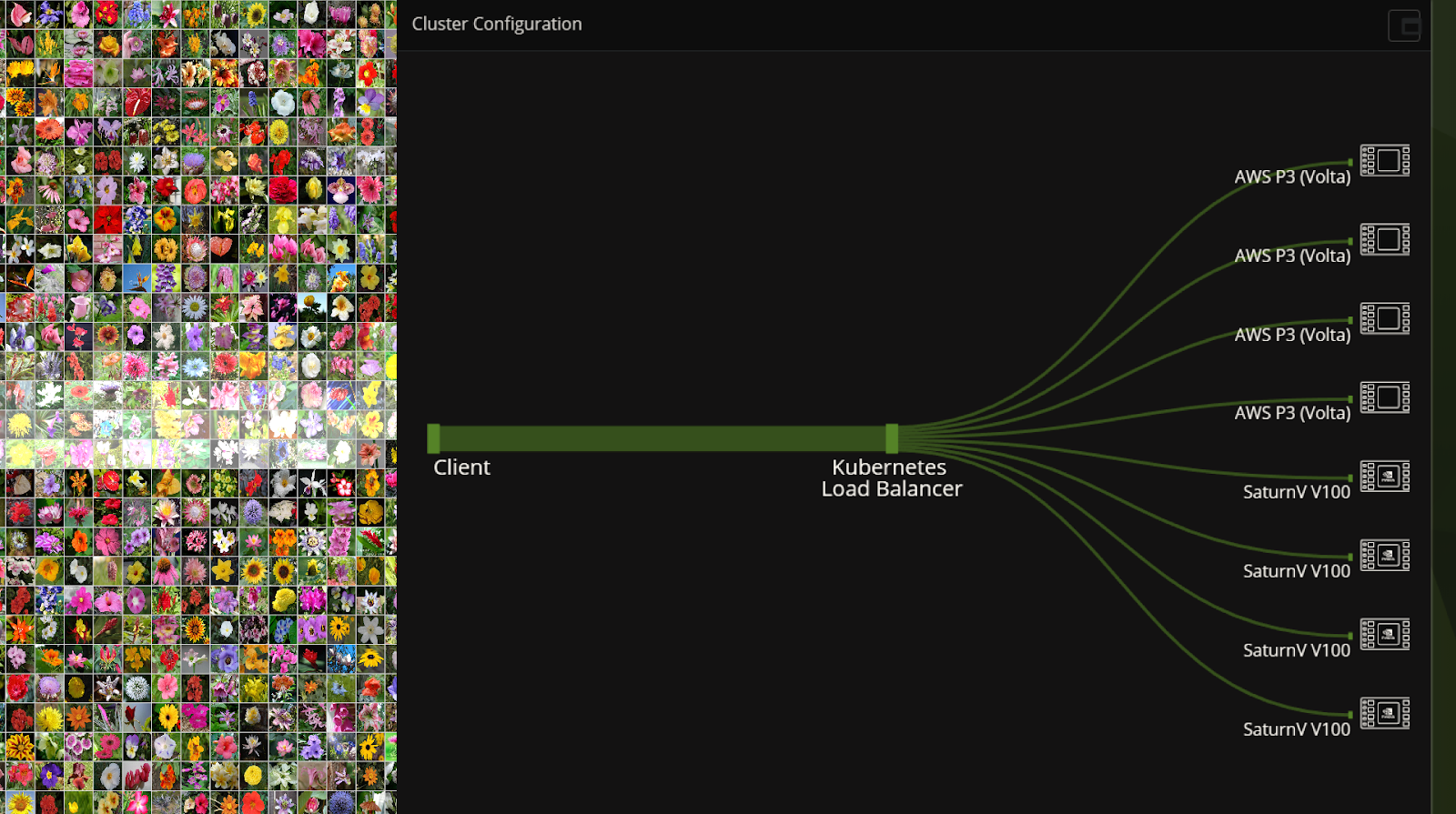
Image showing the scaling of inference workloads using Kubernetes on NVIDIA GPUs deployed on a hybrid on-prem and public cloud deployment
Source: Nvidia
Nvidia’s TensorRT inference accelerator meanwhile, is aimed at developers of inference models. The tool integrated with the Google-made open-source TensorFlow machine learning framework, and adds new layers and features to boost inference for applications such as recommendation systems, neural machine translation, image classification and speech recognition.
As for DALI, this is a service that features a GPU-accelerated library for JPEG image coding and is built to address performance bottlenecks in vision-based deep learning applications. The idea is to help scale the training of image classification systems such as PyTorch, TensorFlow and ResNet-50. DALI is being made available on Amazon Web Services Inc.’s P3 8-GPU instances as well as Nvidia’s own DGX-1 deep learning system.
“Deep learning researchers need their pipelines to be portable,” said Kari Briski, director of accelerated computing software and AI products at Nvidia.
THANK YOU





