NEWS
NEWS
NEWS
NEWS
NEWS
Apache Spark is the tech du jour in Big Data right now. Its ability to provide speedy performance against huge volumes of data has made such a splash that some people are even beginning to question the future of Hadoop. But does Spark really have what it takes to overshadow the world’s hottest Apache open-source project?
With up to 100 times the top performance of the current default processing framework and support from nearly every major vendor in the Hadoop ecosystem, Apache Spark is in the lead to becoming the next primary execution engine for Hadoop and the default path enterprises take to Big Data analytics. The big question is what happens after that.
Spark can be at once both complementary to and competitive with Hadoop. It’s one of several Hadoop-related engines, along with MapReduce, Drill, Impala and others. However, Spark doesn’t need to sit on top of Hadoop’s HDFS file system; it’s just as capable when running atop data sources such as Amazon Web Services’ S3, HBase, Apache Cassandra and others.
One thing is for sure: Spark presents a significant challenge to MapReduce, one of the original core components of Hadoop. The problem with MapReduce, which was taken by Lucene developer Doug Cutting and transformed into the original Hadoop framework, is that its slow, batch nature and high level of complexity can make it unattractive for many enterprises. Spark is both faster and superior in many ways, offering batch, iterative and streaming analysis techniques that are far more capable than MapReduce’s batch processing.
“From a technical point of view, Spark provides a faster and more powerful execution engine,” said Reynold Xin, data engineer and co-founder at Databricks, Inc., the company that leads the Apache Spark project. “It means that businesses and applications are able to use Spark to run their existing workloads faster, and employ more sophisticated workloads that were previously not possible with Hadoop alone.”
Over the last year Databricks has forged partnerships with all of the major players, beginning with Cloudera, Inc. in February of last year, and later with the likes of Hortonworks, Inc., IBM, MapR Technologies Inc., and Pivotal.
“Spark has become one of the things users expect to get when they adopt Hadoop,” said Eli Collins, Chief Technologist at Cloudera. “Spark’s caching system makes it a great engine for highly iterative jobs, and it also has advantages for other types of batch processing, and can work with large data sets.”
Spark offers much more than a mere speed improvement, though. It represents a radical evolution of the original vision for Hadoop as a singularly-purposed batch processing platform. If Spark can be applied to multiple file systems, many people think it could reduce the need for Hadoop in the enterprise.
Then there’s Hadoop’s HDFS, which is a relic from the early days of the project that was not built with the advanced requirements of Spark in mind. One of Spark’s advantages is that it can run on top of file systems other than HDFS. It also executes in memory when operating conditions allow and only offloads data to disk if necessary, an approach that HDFS supports only on a superficial level. That limits its potential to be used in the growing area of real-time analytics.
Ion Stoica, co-founder of Databricks, told TechRepublic that Spark’s biggest advantage is that it reduces the complexity of using Hadoop with MapReduce, which is often cited as a primary obstacle to Hadoop’s widespread enterprise adoption. In Hadoop, it’s necessary to deploy different systems to support different workloads, Stoica said. For example, the Mahout machine learning system might be needed to run Impala for real-time ad hoc queries. Meanwhile, other tasks wouldn’t be able to process. With Spark, this all becomes easier, Stoica said. Workloads are supported by libraries that share the same data, so the same execution engine can be used to interact with them.
Application developers’ lives have been made much easier since MapR began supporting Spark, notes Tomer Shiran, vice president of product management at MapR. That’s because its programming model and API are more natural than MapReduce’s.
“The developer is essentially transforming collections of objects, as opposed to having to express their application as a map and a reduce function,” Shiran said. “Even so, it will take some time for Spark to reach the maturity level of MapReduce.”
Patrick McFadin, chief evangelist for Apache Cassandra at DataStax, said that a growing number of organizations will switch to Spark when it makes sense to do so. “Spark is the heir apparent to MapReduce,” he said.
That’s not to say that MapReduce is valueless, but it’s a ten-year old technology that is no longer evolving as the speed it once did. “MapReduce workloads will still be around for years; it’s not going away,” McFadin insisted. “But Spark has had the benefit of being developed years after MapReduce, so it really is a logical next evolution.”
Spark’s versatility is another crucial factor. “Many advanced algorithms, like machine learning and data streaming, which were previously not possible or extremely inefficient on MapReduce, are now driving rapid Spark adoption,” said Databricks’ Xin.
Databricks demonstrated Spark’s speed last November when it destroyed a benchmark record previously set using Hadoop MapReduce in the Daytona GraySort Test. For the test, which involves sorting 100 terabytes of data, Databricks ran Spark on 206 machines and nearly 6,600 cores on Amazon Web Services cloud. It completed the job in just 23 minutes – smashing the previous record of 72 minutes set by Yahoo! Inc., which used a much larger 2,100-node Hadoop cluster with more than 50,000 cores to complete the test.
“Spark beat MapReduce in the large scale sort benchmark at thirty-times higher-per-node efficiency, without even exploiting the in-memory capability,” said Xin.
Hadoop isn’t standing still, of course. The UC Berkley department where Spark was born has created an alternative file system specifically designed to accommodate the shortcomings of the Hadoop framework. Licensed under an Apache license, Tachyon makes generous use of memory to deliver up to 300 times the throughput of HDFS while also providing almost full backward compatibility with existing HDFS workloads. That combination is bound to bring the project to the fore once Spark takes its place at the gravitational center of the Hadoop ecosystem.
The mind shift is well underway, with a number of major vendors including Red Hat, Inc. and EMC having already thrown their weight behind Tachyon. It’s a only matter of time until the system officially becomes part of the Apache Foundation Software, which will put it on a direct trajectory to replace HDFS.
Some people consider Spark to be a competitor to Hadoop because it doesn’t actually require the Hadoop framework to run. But Spark is not only already part of the Hadoop ecosystem but is also typically used different scenarios.
“The addition of Spark has now set up a condition where we can ingest data at high speed, analyze it in place without ETL [extract, transform and load] and then write the results right back into a Cassandra table,” said DataStax’s McFadin. “If you are powering something like a web site or mobile application, this is a powerful combination.”
While Hadoop remains the obvious choice for data warehousing and offline analysis of large data sets, Spark on Cassandra is a better alternative for applications in which speed is a factor, McFadin said. That’s because, unlike Hadoop, Cassandra is able to perform much lower-latency request handling. When combined with Spark’s rapid data processing abilities it can create accessible views of data much faster than when is possible using the Hadoop framework.
The Spark project encompasses no fewer than four other components, including a stream analytics engine and a structured query interface. It provides out-of-the-box capabilities that previously required learning, setting up and maintaining a mishmash of different technologies. And once users inevitably start shifting their attention away from third-party components to Spark, vendors will follow suit.
So it wouldn’t be a huge surprise if more organizations start to use Spark with Cassandra and other file systems, perhaps eroding Hadoop’s position as the dominant Big Data platform in the enterprise, said Ben Bromhead, co-founder & CTO of Instaclustr Pty Ltd.
“If you’re using Hadoop just against HDFS, you still need a data store or database to run your day-to-day transactional operations,” he said. “Spark and Cassandra’s integration make it really simple because you can directly run your queries against your operational database, and you don’t have to run an entire cluster just dedicated to analytics.”
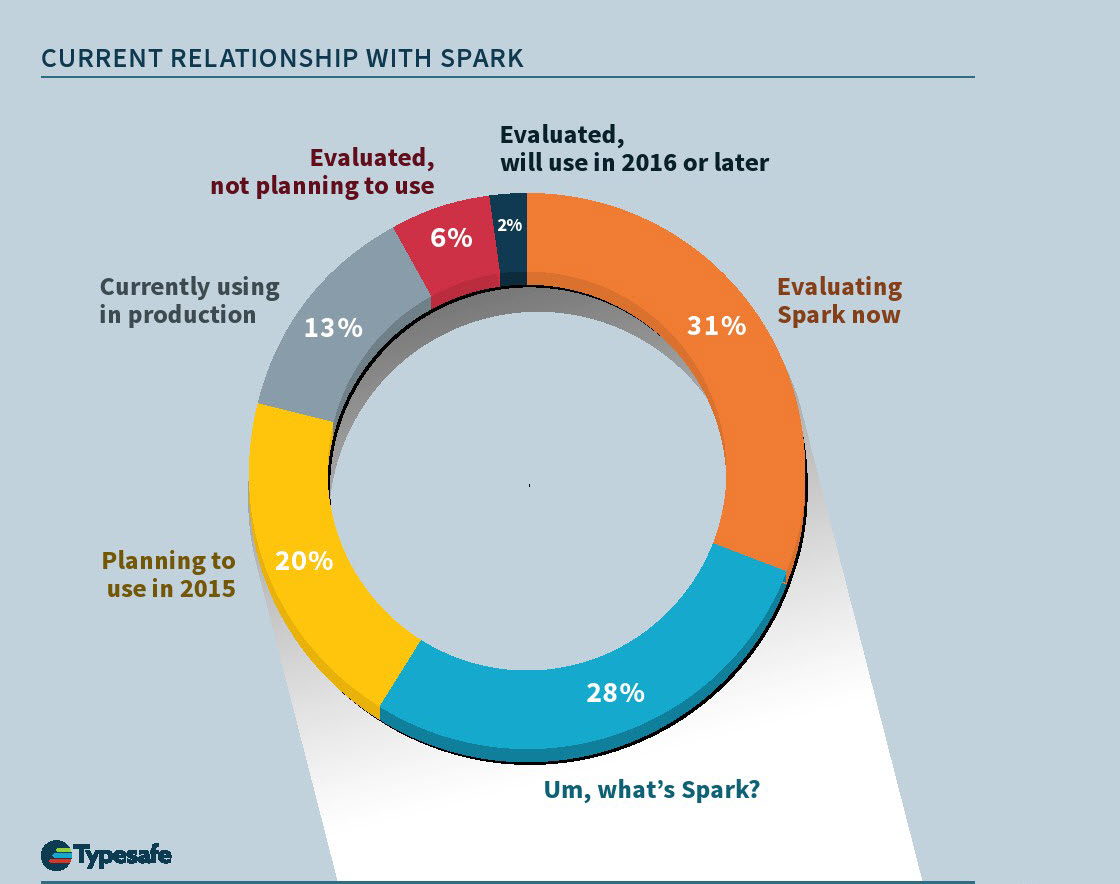
Source: Typesafe, Inc.
Research attests to Spark’s surging popularity. According to a recent survey by Typesafe, Inc., 20 percent of Spark instances in production are now running on Cassandra, compared with 42 percent running on Hadoop’s YARN framework and 26 percent using Apache Mesos. “Hadoop won’t be completely replaced but it will be used in a lot less places where it was previously the only choice for analytic needs,” McFadin predicted.
How much “less used” becomes remains to be seen, but at least in public, the major Hadoop vendors don’t seem too worried about any threat Spark might pose. “Spark is a component in the Hadoop ecosystem,” insisted MapR’s Shiran, who pointed to Hadoop’s superior data warehousing and offline analysis as its main strengths. “I’m not aware of any other storage system out there that is suitable for storing Big Data and supporting in-situ processing and analytics.”
Cloudera’s Collins had a different take, saying that it was not so much a question of whether Spark threatens Hadoop’s dominance, but whether or not an alternative stack that also contains Spark could emerge to displace it. He admits that scenario is theoretically possible, but if it ever happened, Spark wouldn’t be the differentiating factor. And in case a rival stack did contain Spark, “there would be no reason for that stack not to leverage other components of the Hadoop stack, so it would likely end up being just another Hadoop stack,” Collins predicted.
The SQL-on-Hadoop segment will probably take the biggest hit, since most of the components in that space don’t offer any inherent advantage over using the native structured query capabilities of Spark. The latter is both simpler, enabling users to seamlessly run their requests alongside analytic workloads, and in some scenarios (particularly when compared to Hive) much faster as well.
Simplicity is a big advantage with Spark’s real-time engine compared to a structured query interface because it enables developers to leverage the same syntax they’re using for batch processing instead of learning an entirely new technology. But it’s heavily limited by the inherently batch-oriented architecture of the engine.
Spark Streaming has higher latencies than purpose-built alternatives such as Storm and Samza that ingest data immedately as it comes in. Still, the native integration is a major advantage that could help lower the barrier to entry associated with real-time analytics for many organizations and thereby potentially serve as an on-ramp to more mature options in the Hadoop ecosystem, driving adoption.
Databricks’ Xin wouldn’t speculate on the potential disruption to other projects, but he did say that advocates of Hadoop have nothing to fear, at least not for the foreseeable future.
“Hadoop is developing as an important data ecosystem, and many Spark deployments are in the Hadoop environment,” said Xin. “The goal of the Spark project is not to threaten or replace Hadoop, but rather to integrate and interpolate well with a variety of systems to make it easier to build more powerful applications.”
Maria Deutscher contributed to this report.
photo credit: unfetteredhowl via photopin cc; Adi ALGhanem via photopin cc
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.