







 NEWS
NEWS
NEWS
NEWS
NEWS
Nearly nine months after launching out of stealth with $15.2 million in funding, Datos IO Inc. is announcing the fruits of two years of development on technology to protect data in the new era of distributed databases.
RecoverX is being touted as the industry’s first scale-out data protection software for what some people are calling the “third platform” of computing after mainframes and client/server. The Economist defined third platform as being based on a cloud model in which online computing creates “interaction with all manner of devices, including wirelessly connected ones such as smartphones, machinery and the Internet of things.”
That makes backup and recovery a mess.
Or put another way, databases are getting bigger by orders of magnitude while also adopting a replication model, which makes the task of identifying exactly what data to preserve more difficult. “A five-terabyte database used to be very big; you’re now dealing with 20- and 30-terabyte databases,” said Tarun Thakur, CEO of Datos.
And there’s no such thing as a single canonical copy of data anymore. NoSQL databases achieve their scale-out functionality by “sharding” databases across multiple machines or replicating data between nodes in a cluster. The fact that multiple copies of the data may exist at any given time makes it difficult to figure out which copy represents the truth. But the approach has the advantage of being cheaper and far more scalable than the traditional model of storing all data in one place.
“You don’t run Cassandra on a SAN (storage-area network). You run it on local storage,” Thakur said. “If data is distributed across multiple nodes and every write is duplicated three times, you need a way to convert three copies into one copy for backup on secondary storage.”
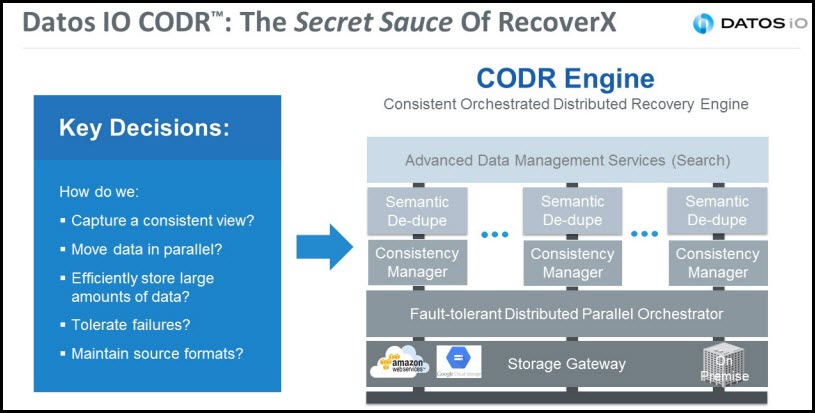
That’s the problem Datos IO says it’s solved. It uses scalable versioning and semantic deduplication to reliably protect data in distributed environments such as Cassandra and MongoDB. It does this with a proprietary architecture called Consistent Orchestrated Distributed Recovery (CODR) that breaks from the traditional single-point-of-truth media server approach.
RecoverX moves data onto secondary storage, checking time stamps of every value and performing key- and value-level analysis to isolate the most current version. The result is what Thakur called one “golden copy” of the data. “There is so much savings on storage that it will pay for the software itself by a significant order of magnitude,” he said. There are more details in this white paper.
Scalable versioning enables enterprises to protect both Apache Cassandra and MongoDB at any interval and granularity, the company said. Recovery takes minutes and semantic de-duplication saves up to 70 percent on secondary storage costs.
The first release of RecoverX supports Apache Cassandra (v2.0, v2.1), DataStax DSE (v4.5, v4.6, v4.7, v4.8) and MongoDB (v3.0, v3.2). It can also handle a wide variety of secondary storage options such as Amazon S3 and Google Cloud Storage. The initial version supports environments of up to 30 nodes.
The product comes in standard and enterprise editions on an annual subscription basis. Capacity-based licensing starts at $5,250 for the first terabyte with volume discounts. There’s also a free trial version.
THANK YOU





