



 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
A little-known startup called Hazelcast Inc. is hoping to steal some of the limelight from popular open-source projects Apache Spark and Apache Flink, launching what it claims is a faster and lower-latency distributed processing engine for big data.
The new open-source solution Hazelcast Jet, announced today, is designed to work with the company’s flagship in-memory data grid, which provides storage functionality for incoming big data streams. The idea is that with both computation and storage being kept in-memory, Hazelcast Jet can perform parallel execution on incoming data, thereby enabling applications to operate in as close to real-time as it’s possible to get.
The key difference between Jet and competing technologies such as Spark and Flink is that it’s built on top of something called a “one-record-per-time architecture,” the company said. This means Jet can process incoming data records as soon as possible, whereas Spark and Flink both accumulate records into micro-batches before processing them. As a result, Jet simply works faster, thereby lowering latency for the applications it powers, the company claims.
Another advantage Jet has over Spark and Flink is that it can easily be embedded in applications, inside application servers, Hazelcast Chief Executive Greg Luck told SiliconANGLE in an email interview. “This is super simple – there are no moving parts,” he said. “And batch processing problems in particular can be expressed very simply using Jet distributed form of java.util.stream. Word count, the classic Big Data application, can be expressed in a single line of code.”
Luck said he believes Jet’s close-to-real-time data processing capabilities will make it appealing for Internet of Things, social media and e-commerce applications that demand virtually instantaneous data processing. He also said that Jet is much easier to deploy than something like Spark or Flink, and it can be fully embedded for equipment manufacturers and microservices, which makes it easier for manufacturers to build and maintain next-generation systems.
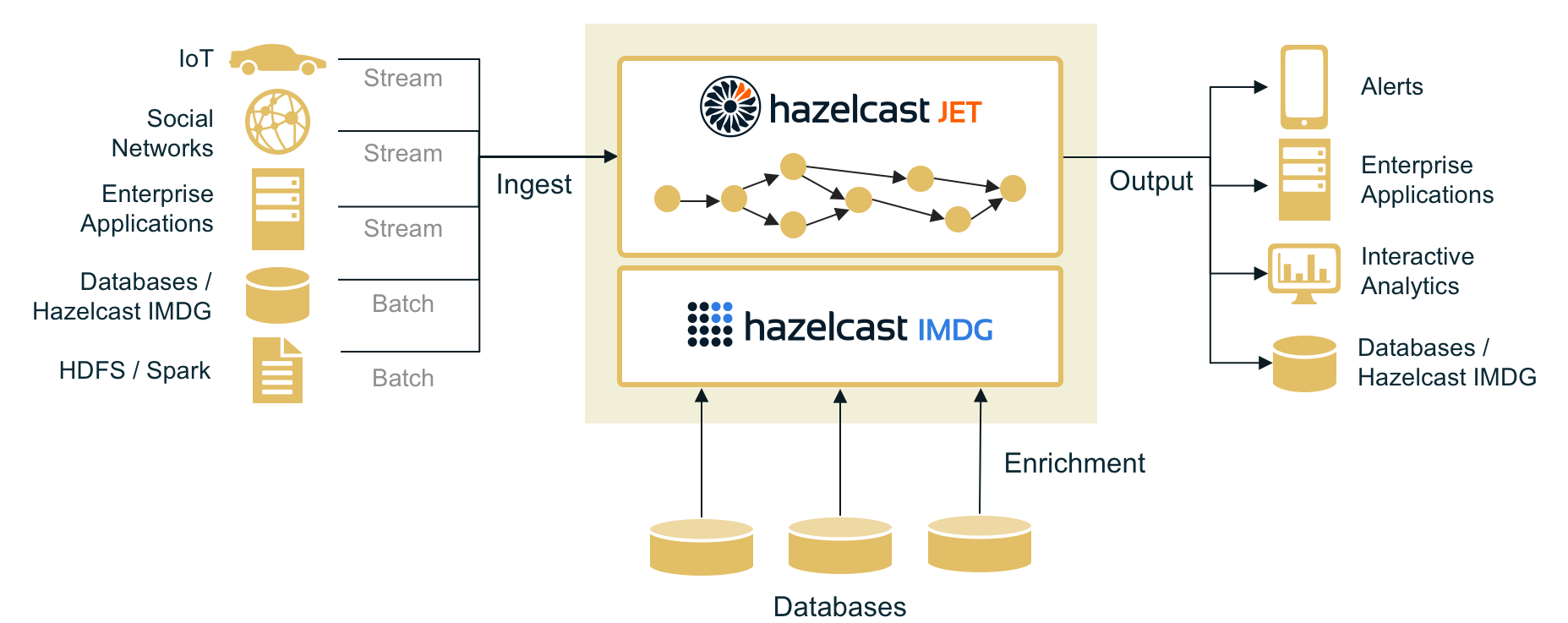
“We believe that the Hadoop and Spark ecosystems are too complex to program and to deploy and have set out to bring Hazelcast’s legendary simplicity to big data,” Luck said in a statement. “We have designed it as a general purpose engine for the intersect of big data programmers and Java programmers. But if you are already a Hazelcast user or have data in Hazelcast it will be the easiest way to solve your Big Data problems.”
THANK YOU





