









 NEWS
NEWS
NEWS
NEWS
NEWS
 Matei Zaharia, an assistant professor of computer science at MIT and the initial creator of Apache Spark, took the stage at Strata 2014 to speak about the Spark open source project and about the way companies are using it. Currently the CTO of Databricks, Zaharia offered the audience some insight into where the edge in Big Data will be.
Matei Zaharia, an assistant professor of computer science at MIT and the initial creator of Apache Spark, took the stage at Strata 2014 to speak about the Spark open source project and about the way companies are using it. Currently the CTO of Databricks, Zaharia offered the audience some insight into where the edge in Big Data will be.
According to him, to answer why we have a Big Data problem today, a little bit of background info is required.
“It has become dramatically cheaper to store data so, in the past 10 years the cost of storing large volume data has fallen by a factor closer to 20 – depending how you count,” said Zaharia.
It’s due to both increasing storage density of things like hard disks, but also to the revolution in software.
Motivated by innovative web companies like Google and Facebook, there’s been a new architecture for large scale data storage that uses commodity clusters and software like Hadoop. This has made it much cheaper to store large data sets than traditional methods.
Today, this kind of commodity cluster architecture is broadly available from multiple vendors and it’s becoming the standard for storing large data sets.
“If we take this into account, and we see that Big Data storage is becoming commoditized, how will organizations gain an edge in Big Data?” asked Matei Zaharia.
The answer is very simple: “what will matter next is what you can do with the data. Just storing large amounts of data (which was a competitive advantage for some organizations at first) will no longer be enough.”
Matei Zaharia thinks two things will lead to gaining an edge:
“It’s a whole new end-to-end process, from the point where the data comes in, to the point where someone writes a computation or a query to run on it, and then to the point where you can make a business decision based on it,” explained Zaharia.
“There are many examples of data sets being collected by companies, but so far only a few companies, such as Google, managed to come up with sophisticated algorithms to gain the most value out of it,” Zaharia went on.
From Zaharia’s point of view, achieving the best speed and sophistication has usually required separate, non-commodity tools that don’t run on these commodity clusters – often proprietary and quite expensive.
In comparison, Apache Spark is a compute engine for Hadoop data that runs on Hadoop clusters and is designed to address this problem.
Matei Zaharia boasted: “Spark is fast. It can be up to 100x faster than MapReduce in real-user workloads. You can use the same commodity hardware that you have to run at speeds that were previously only attainable with a very specialized and expensive software you’d have to purchase.”

Spark supports sophisticated algorithms; it has been designed from the beginning to support machine learning and Graph algorithms, and has a growing set of packages on top, including SQL, real-time stream processing, libraries of machine learning and Graph functions.
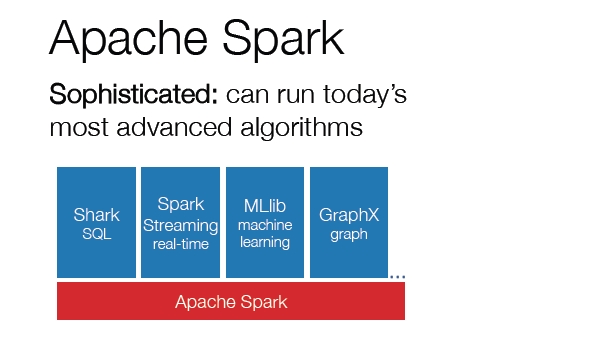
“Spark is fully open source. Since 2010, it has become one of the most active projects in Big Data. Spark has actually taken over Hadoop MapReduce and every other engine that we’re aware of in terms of number of people contributing to it,” added Zaharia.
Commercially, there’s hasn’t been a big buzz around Spark, but the actual developer community is getting things done.

Spark brings the top-end data analysis – the same high performance and high level of sophistication you get with these expensive systems – to commodity Hadoop clusters, and runs in the same clusters to allow users to do more with their data.
To show exactly how speed and sophistication come into play, Zaharia presented four use-cases.
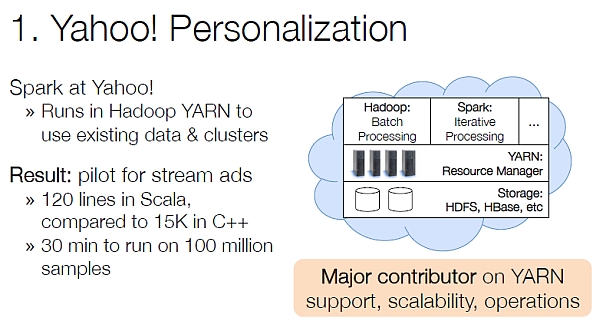
1. Yahoo! Personalization
Yahoo! properties are highly personalized to maximize relevance. Yahoo! spent an enormous amount on personalization in order to make every one of its properties highly relevant to the person visiting.
At Yahoo! reaction must be fast, as stories change quickly. Best algorithms are highly sophisticated; they run Spark inside Hadoop YARN so that they can use the existing data and clusters.
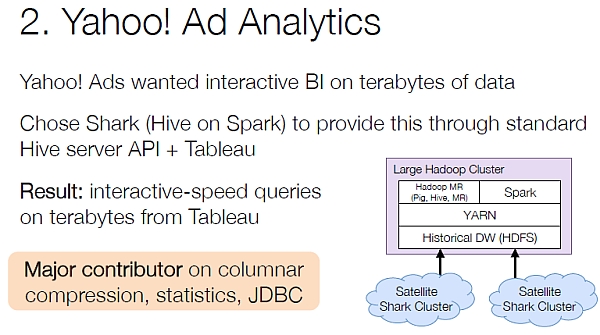
2. Yahoo! Ad Analytics
Yahoo! Ads wanted interactive BI on terabytes of data and they chose Spark (which is Hive implemented on top of Spark) do this. The advantage is that Shark uses standard Hive server API, so that any tool that plugs into Hive (like Tableau), automatically works with Spark.
Result: interactive-speed queries on terabytes from Tableau.
The Yahoo! Ads team has been a major contributor to Spark, including features like columnar compression, statistics and JDBC support.
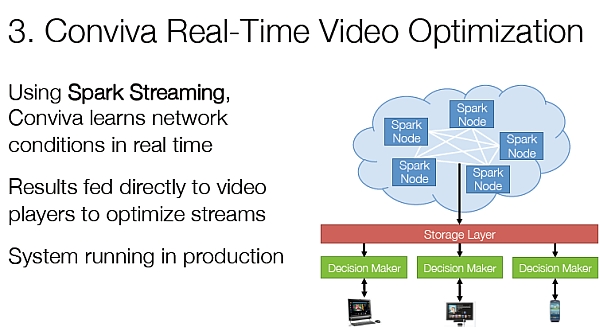
3. Conviva Real-Time Video Optimization
Conviva is one of the largest video companies on the internet, managing over 4 billion video streams per month; this is more than any organization, except YouTube. The way they do it is by dynamically select and optimize sources – while the video is playing – to maximize quality.
This task is extremely time critical: as much as 1 second buffering time reduces viewer engagement, therefore you need to react before the buffer runs out, switching to a different stream. Conviva uses Spark Streaming to achieve this. They learn network conditions in real-time and feed it directly into the video player, to optimize the streams.
4. ClearStory Data: Multi-source, Fast-cycle Analysis
Multi-source requires some complexity sophistication to merge different data sources, and fast-cycle means they want to react fast.
They have different data sources both within the business and externally, such as social media or public data feeds, to merged in order to produce insights. This can be done in seconds to minutes. Using Spark, ClearStory has built this highly interactive visual application that lets business users combine data sources, achieving real results from the data, updated in real-time.

Matei Zaharia concluded the quick tour of what can be done with Spark, clarifying the reason he founded his company: “We started DataBricks to bring Spark to the widest possible audience.”
Zaharia wrapped his presentation, stating, “Big Data will be standard: everyone will have it.”
The first Big Data systems made a new class of applications possible, but nowadays organizations will gain an edge through speed of action and sophistication of analysis, with which they can draw value from data.
Future data processing platforms will not only be required to scale cost-effectively, but to allow ever more real-time analysis, supporting both simple queries and today’s most sophisticated analytics algorithms. The Apache Spark platform aims to transform large-scale data analysis.
Matei Zaharia is the creator of Apache Spark and the CTO of Databricks, the company “working to revolutionize what you can do with Big Data.”
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





