









 NEWS
NEWS
NEWS
NEWS
NEWS
Google’s Cloud Dataproc service, which has been in beta since last September, has finally hit general availability, the company said.
Cloud Dataproc is a service that allows users take advantage of open-source data tools like Hadoop and Apache Spark for batch processing, querying, streaming, and machine learning. It comes with automation tools that allow clusters to be created quickly, along with the ability to save money by turning clusters off when they’re not needed. The service also supports MapReduce, the Apache Pig platform for writing programs, and the Apache Hive data warehouse, and has been boosted by a number of enhancements since entering beta.
“While in beta, Cloud Dataproc added several important features including property tuning, VM metadata and tagging, and cluster versioning,” said Google product manager James Malone in a blog post.
Google is pitching Cloud Dataproc as a complimentary tool to its Cloud Dataflow service for batch and stream processing. In addition, Google said the underlying technology for Dataflow has already been accepted as an Apache incubator project, called Apache Beam.
Like all of Google’s cloud products, the company is pricing it very low, at just $0.01 per hour per virtual CPU.
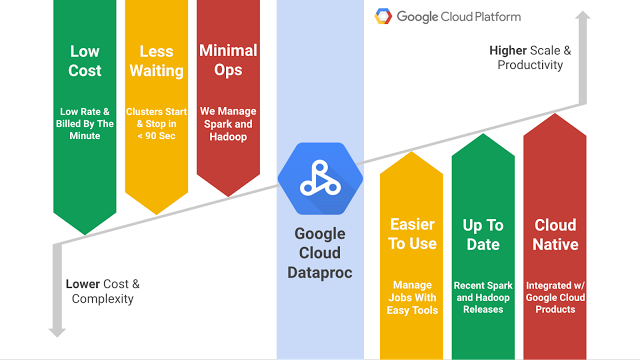
With the launch of Cloud Dataproc into general availability, Google gets another weapon in its armory to take on Amazon Web Services and Microsoft Azure. Both companies offer their own Hadoop-based Big Data services, and there are many startups doing the same thing too. However, Google’s offering is distinct in that it plays nicely with Google’s other cloud services, including Google Cloud Bigtable, BigQuery and Google Cloud Storage.
You can learn more about Cloud Dataproc here.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





