









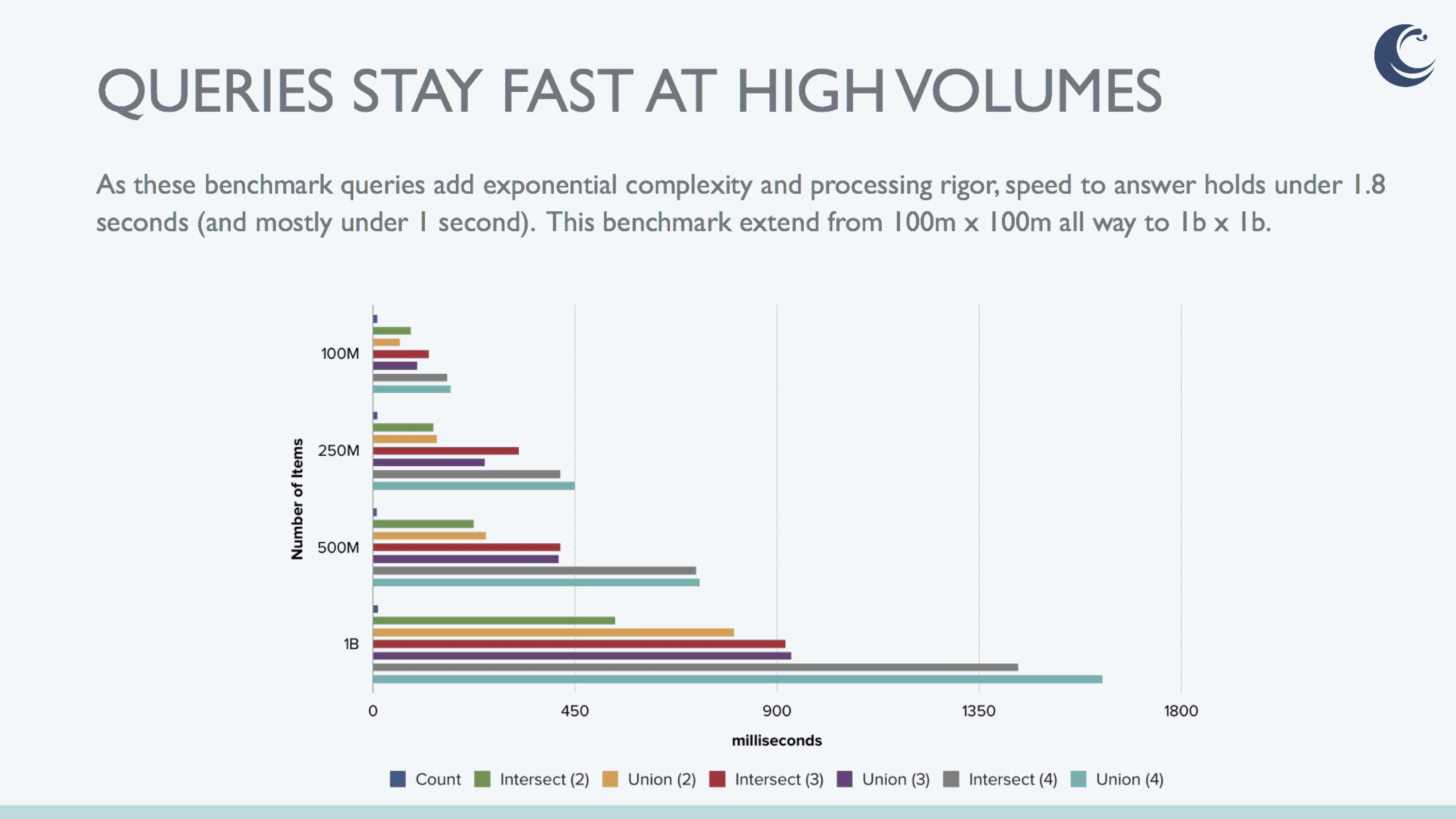
 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
We ask a great deal of modern machines. Stuffed full of information and imbued with cognition, modern computers do our bidding, ideally in real time. Yet for all the advances in data management, the ability to quickly retrieve and analyze data remains a critical obstacle in today’s digital economy. One startup is rethinking established technology for new purposes, applying bitmap indexing to massive data sets in an open, distributed fashion.
Launching its public beta today ahead of the Open Source Convention, Austin, Texas-based Pilosa works by decoupling the index from data storage and optimizing it for massive scale. The result is dramatically accelerated query speeds across multiple large, structured data sets, according to the company. In an effort to help read speeds catch up to write speeds for database management, Pilosa’s in-memory index expedites queries to existing databases as well as the process of joining data from multiple sources. Pilosa makes a terabyte of data respond to queries as if it were 10 megabytes.
“We’re a new category of software,” said Pilosa Chief Executive Higinio (H.O.) Maycotte. “We like to sit on top of any large data set. You might have elastic search — we can sit on top of that. You might have Neo4j — we can sit on top of that, too. NoSQL database, all the components in a stack for machine learning, reporting and analysis could use Pilosa as the point of data querying and not worry about the other components. If you have data highly fragmented across sources, we’re a single stop.”
Why bitmap indexing? Well, it’s a way to rapidly translate structured data into Boolean code (zeroes and ones), converting data into its rawest form for easy computer digestion. Ongoing efforts to speed up data queries on massive data sets have focused largely on compressing data for bitmap indexing, but Pilosa is taking a unique approach, altogether avoiding the concept of compression. By breaking down data sets, Pilosa turns each variable into a “yes or no” question, where 0 could represent “yes” and 1 could represent “no.” This process actually expands the number of columns in a data set, but these bit-sized data points are much easier for a computer to understand.
For example, a taxi service’s data set could have dozens of variables to consider during rush hour, such as fare rates, traffic flow, weather and pick-up/drop-off locations. Pilosa’s bitmap indexing process would take each variable, like weather, and break it down into a series of questions that can be answered with a simple “yes” or “no.” Is the weather sunny? Yes or no? Is the weather partly cloudy? Yes or no? Is the weather stormy? Yes or no?
While most structured data sets use similar processes of parallelizing data in a Boolean code bitmap index, Pilosa’s differentiating factor is the distribution method for speeding up queries. Instead of cramming millions of data points into a single machine to run algorithms against the data, Pilosa slices it up to distribute across multiple machines.
“When we ask a question of that data, to compare millions of [index] rows you can do just the work of, say, four million bits on one machine and the next four million on another machine. The heavy computation is distributed across different nodes in the cluster,” explained Pilosa engineer Travis Turner.
In this way, Pilosa is democratizing a querying process typically reserved for large companies with endless resources and exotic hardware, like graphics processing units, which can require skilled and dedicated staff. With a small footprint software solution that sits on top of any persistent storage solution, Pilosa doesn’t displace any existing IT infrastructure. According to the company’s FAQs, they’ve addressed the underlying problem by creating an index independent of storage, optimized for high cardinality data at scale.
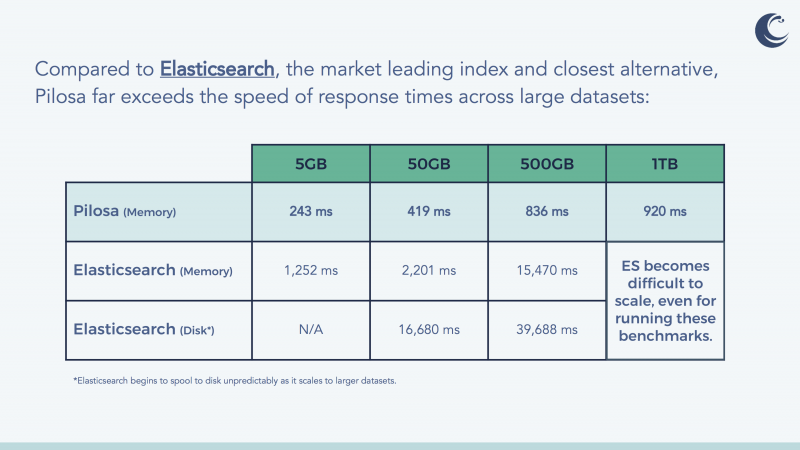
Borne from Umbel, Maycotte’s previous startup for securely managing consumer data, and emboldened with nine patents in its arsenal, Pilosa takes on ElasticSearch and Neo4j in traditional enterprise settings. Many legacy tech giants also have their own bitmap indexing services, including Hewlett Packard Enterprise Co.’s Vertica, IBM Corp.’s DB2 BLU and Oracle Corp.’s Exadata. With a seemingly agnostic approach to the software layer, Pilosa claims to support any and all data sources, as well as the ability to add streaming data into pre-existing indexes through its API.
Pilosa’s inaugural product is launching as an open source offering, available today on GitHub, as the startup hopes to attract collaborating developers and use cases to prove its disruptive methodologies (alternatively you can pay a fee to add Pilosa to the stack and access premium performance modules). Pilosa will also face the challenges of balancing free, open source solutions with the eventual need to generate revenue. Should Pilosa’s open source efforts go according to plan, the startup could soon be armed with real-world use cases and a supportive ecosystem to lure partners, clients and investors with an eye for urban development (think smart cities), bioinformatics (think gene therapy for cancer) and security (think network integrity).
To succeed in such highly regulated industries, Pilosa’s playing up its bitmap indexing methods for security purposes as well. “Because Pilosa doesn’t contain metadata but is an abstraction of 0s and 1s, it allows the opening of that index to parties that might not have otherwise been able to access information for research or analytics, because of its sensitive nature,” said Maycotte.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





