















 CLOUD
CLOUD
CLOUD
CLOUD
CLOUD
Google LLC continues to make progress on the machine learning front, announcing today the general availability of its Cloud Text-to-Speech service as well as improvements to its Cloud Speech-to-Text service, which remains in beta.
Google’s Text-to-Speech service is intended to help companies develop better conversational interfaces for the services they supply. With the service, Google is targeting three main markets, including voice response systems for call centers, for which Cloud Text-to-Speech can provide real-time, natural-language conversation.
Google is also targeting the “internet of things” sector, specifically products such as car infotainment systems, TVs and robots, enabling these kinds of devices to talk back to users. Finally, it’s aiming at applications such as podcasts and audiobooks, which convert text into speech.
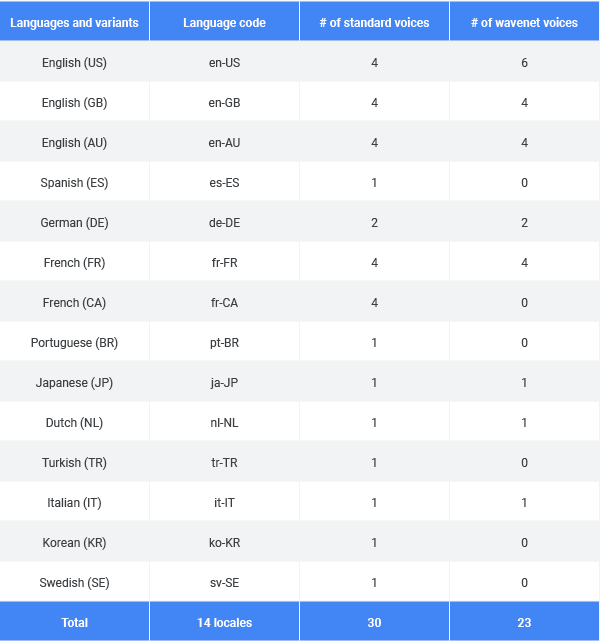
Google Text-to-Speech uses several different technologies, including the one it has used for years and two that were developed by its DeepMind artificial intelligence unit that use WaveNet, which is a deep neural network for generating raw audio. When it was launched in beta earlier this year, the service had 32 different voices in 12 languages. Now it boasts 17 languages in total with 56 voices, 26 of them from WaveNet, Google said in a blog post.
In addition, Google announced a new service called Audio Profiles for use with Text-to-Speech that enables users to optimize the service for playback on different kinds of hardware.
“You can now specify whether audio is intended to be played over phone lines, headphones, or speakers, and we’ll optimize the audio for playback,” the company said. “For example, if the audio your application produces is listened to primarily on headphones, you can create synthetic speech from Cloud Text-to-Speech API that is optimized specifically for headphones.”
Google said that new features for its Cloud Speech-to-Text service announced during its Cloud Next conference last month have now been made available, too. As the name implies, Cloud Speech-to-Text does the opposite of Text-to-Speech. It’s essentially a transcription service that can listen to human voices and record what they say.
The service has already impressed users for its ability to add proper punctuation such as commas and periods to its text output, and now the company is further improving things with new multichannel recognition features for transcribing audio with more than one speaker in situations when those speakers are using a pair of stereo channels.
And for situations where multiple speakers are using a single channel, Google uses a feature called “speaker diarization” to separate these voices.
That lets you input the number of speakers as an API parameter and, through machine learning, Cloud Speech-to-Text will tag each word with a speaker number, the company said. Speaker tags attached to each word are continuously updated as more and more data is received, Google added, so the service becomes increasingly more accurate at identifying who is speaking and what was said.

Other new features for Cloud Speech-to-Text being added today include “language auto-detect,” which enables software applications to detect automatically which language speakers are using, allowing them to use more than one if they wish. Google is also adding a new feature called word-level confidence scores, which allows developers to build apps that can highlight specific words and then, depending on the score, write code to prompt users to repeat those words as needed, to avoid any mistakes with interpretation.
For example, Google explained, if a user says “please setup a meeting with John for tomorrow at 2 p.m.” into an app, the app creators can decide to prompt the user to repeat “John” or “2 p.m.” if either have low confidence. But it won’t reprompt for “please” even if has low confidence, since it’s not critical to that particular sentence, Google said.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





