















 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
Japan’s Fujitsu Laboratories is trying to address the demand for faster processing in big-data systems that handle analytics workloads.
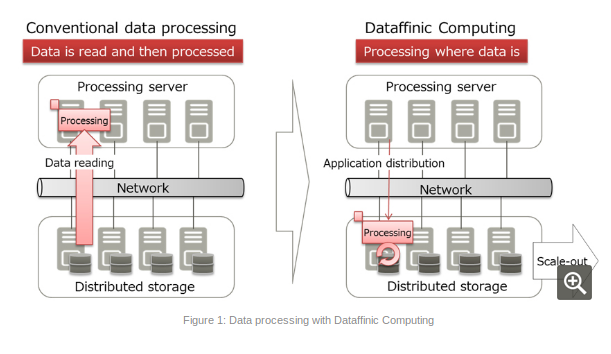
Today the Japanese company said it’s created a new technology that can help high-speed processing of big data in distributed storage systems, where information is stored across multiple drives. The new technology was implemented on the open-source Ceph distributed storage framework, and Fujitsu reckons it works well enough that it can eliminate bottlenecks that occur when servers attempt to read data from such storage systems.
In a blog post outlining what it calls “Dataffinic Computing,” Fujitsu engineers said the massive volumes of data that flow between storage and servers are the main cause of latency in analytics systems. But by processing that data in storage, they reckon they can speed things up because there’s no need to move that data in the first place.
Dataffinic Computing works by connecting multiple servers via a network while maintaining the original storage functionality. The approach breaks down unstructured video and log data and stores it in a state where individual bits can be accessed and crunched more readily, Fujitsu said.
“This means that the pieces of data scattered across the distributed storage can be processed individually, maintaining the scalability of access performance and improving the system performance as a whole,” Fujitsu’s engineers claimed.
Fujitsu’s system also can predict the storage resource requirements needed to maintain the data as it’s being analyzed.
“Storage nodes face a variety of system loads to safely maintain data, including automatic recovery processing after an error, data redistribution processing after more storage capacity is added, and disk checking processing as part of preventive maintenance,” Fujitsu’s engineers wrote. “This technology models the types of system loads that occur in storage systems, predicting resources that will be needed in the near future. Based on this, the technology controls data processing resources and their allocation, so as not to reduce the performance of the system’s storage functionality.”
Fujitsu said the prototype of its Dataffinic system consisted of five storage nodes and five servers linked by a 1-gigabit-per-second network. The engineers measured its data processing performance by extracting objects such as people and cars from 50 gigabytes of video data.
The engineers said the Dataffinic system could process this data in just 50 seconds, which is a tenfold increase over the 500 seconds it took to process the data using conventional methods.
“This technology enables scalable and efficient processing of explosively increasing amounts of data,” Fujitsu’s engineers said.
Analyst Holger Mueller of Constellation Research Inc. said Fujitsu’s new technology could be useful because storage is key for next generation software applications that rely on big data.
“Enterprises need to persist data for temporal analysis, record keeping and statutory regulation,” Mueller said. “So it’s key for storage hardware makers to innovate and cope with larger and larger amounts of data that must be stored and processed. It’s good to see the R&D investment yielding in new high performance storage options.”
The next step will be to verify the technology with commercial applications. If it works reliably, Fujitsu plans to bring a new product based on the architecture to market by 2019.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





