AI
AI
AI
AI
AI
Amazon.com Inc. has come up with a new artificial intelligence system that can train digital voice assistants such as Alexa to learn new speaking styles, similar to a newsreader for example, in a matter of hours.
In a blog post today, Trevor Wood, Amazon’s applied science manager, said the new text-to-speech system could replace traditional methods of voice training that typically require actors to speak in the target style for tens of hours in order to train models.
“To users, synthetic speech produced by neural networks sounds much more natural than speech produced through concatenative methods, which string together short speech snippets stored in an audio database,” Wood wrote. “With the increased flexibility provided by [our system], we can easily vary the speaking style of synthesized speech.”
Amazon, which refers to its new model as “neural text-to-speech,” or NTTS, said there are two key components to it. One is a “generative neural network” that works by converting sequences of phonemes, which are distinct units of sound that distinguish one word from another, into sequences of spectrograms. Those, in turn, are a visual representation of the spectrum of frequencies of those sounds, since they vary over time. The spectrograms are said to “emphasize features that the human brain uses when processing speech,” Wood said.
The other component is known as a “vocoder,” which helps to convert those spectrograms into a continuous audio signal used to train the text-to-speech model.
The complex technical processes are detailed in Wood’s blog post, but the most important thing is that it seems to work just fine. The new training method can combine neural text-to-speech speech data with just a few hours of supplementary data to produce a model that can distinguish between elements of speech both unique to, and independent of, a particular speaking style.
Here’s an example of the older, concatenative method of speech:
And here’s an example of the neural text-to-speech trained voice in newsreader style:
“When presented with a speaking-style code during operation, the network predicts the prosodic pattern suitable for that style and applies it to a separately generated, style-agnostic representation,” Wood wrote. “The high quality achieved with relatively little additional training data allows for rapid expansion of speaking styles.”
Wood said Amazon’s research shows that listeners have a big preference for voices created by the neutral text-to-speech method over traditional concatenative synthesis. In fact, the NTTS method was rated almost as high as normal human speech itself:
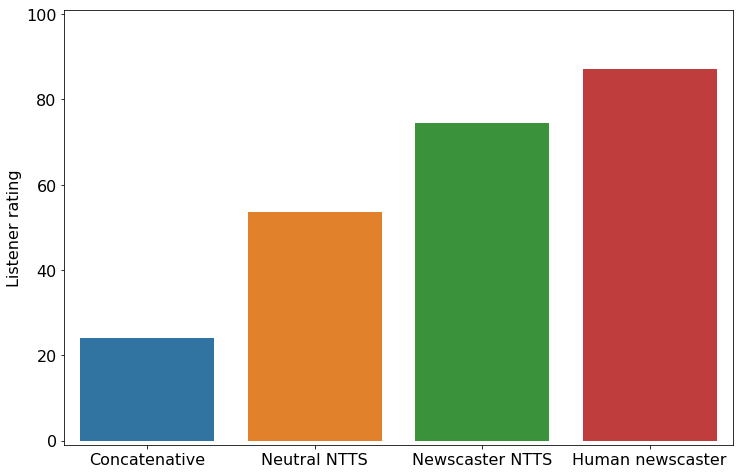
“The preference for the neutral-style NTTS reflects the widely reported increase in general speech synthesis quality due to neural generative methods,” Wood said. “The further improvement for the NTTS newscaster voice reflects our system’s ability to capture a style relevant to the text.”
Amazon has published a series of whitepapers on its research, available here, here and here.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.