







 INFRA
INFRA
INFRA
INFRA
INFRA
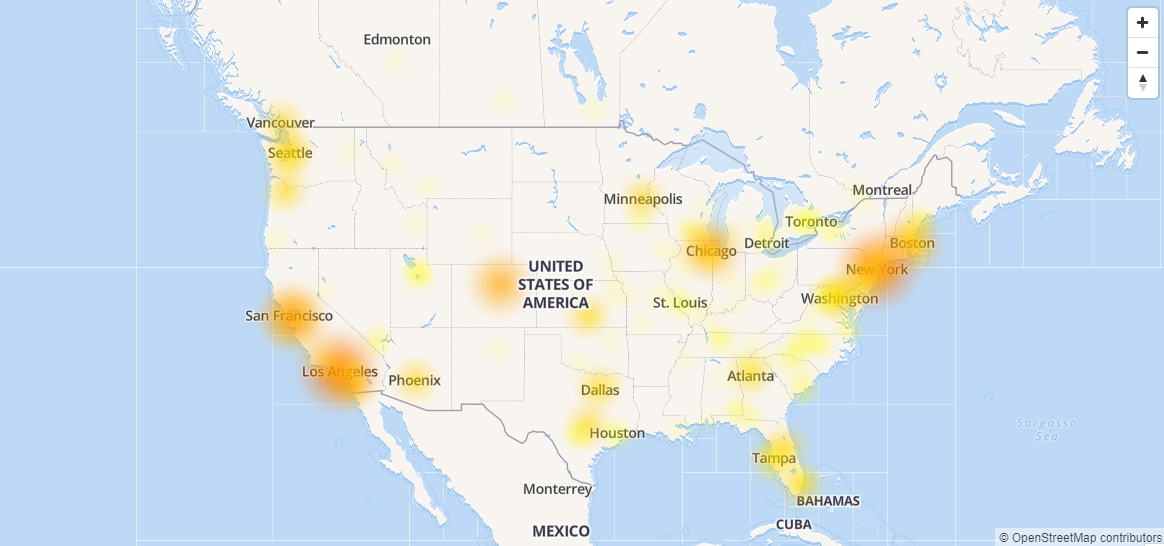
Cloudflare Inc. this morning experienced a brief but widely felt service disruption that made many major websites inaccessible worldwide.
The outage (pictured) started at 9:52 a.m. EDT and lasted for more than an hour. Down Detector, a service that tracks website outages, received user reports of “502 Bad Gateway” errors for sites such as Pinterest and BuzzFeed and business applications such as Dropbox. Down Detector itself was knocked offline for a short period.
Even some sites that don’t rely on Cloudflare’s content delivery network were affected. The BBC reported that Coindesk, a major cryptocurrency and blockchain news blog, briefly displayed incorrect pricing information for bitcoin after the outage hit some of its data providers.
Certain secondary Cloudflare services were still experiencing issues more than two hours after the company brought its platform back online. Cloudflare Analytics, which helps site operators track user traffic, stopped displaying new data and web request logs were being delivered with a delay.
The downtime was apparently caused by an internal operational error. In a series of tweets, Cloudflare Chief Executive Matthew Prince detailed that a “massive spike in global CPU usage” took down both the provider’s primary and its backup systems. Prince pledged that the company will put new protections in place to insulate its backup systems from potential future outages and ensure they can kick into action as intended.
The reason why the disruption had such a big impact on the web has to do with Cloudflare’s central role in processing global internet traffic. More than 16 million sites rely on the company’s platform to load pages for users, as well as to fend off online threats such as distributed denial-of-service attacks.
Large-scale outages at major internet companies don’t occur too frequently, but the impact is often global when they do happen. In June, a technical issue caused YouTube, Gmail, G Suite and other core Google LLC products to become unavailable for four hours. It also caused disruptions for external services such as Snapchat that run on the search giant’s cloud platform.
“In 2019, with automation software available for all deployment tasks downtime caused by human error is simply no longer acceptable, Robert Reeves, co-founder and chief technology officer of database release automation software provider Datical Inc., told SiliconANGLE. “It’s time for this to stop.”
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





