BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
Amazon Web Services Inc. said today that it’s placing more importance on “data resiliency” within its flagship Amazon Elastic Block Store service with the addition of a new feature it’s calling “crash consistent snapshots,” available for subsets of EBS volumes.
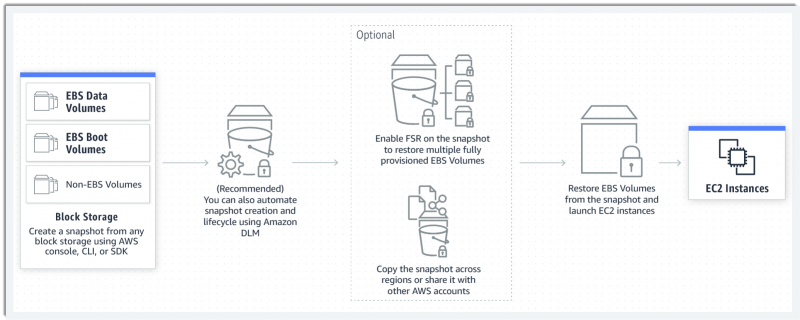
The new feature makes it simpler and more affordable to create “multivolume snapshots” of specific EBS volumes linked to a single Amazon EC2 instance, rather than taking a snapshot of all of the volumes attached to that instance.
In a blog post, the company explained that many customers use Amazon EBS for mission-critical applications and they regularly back up their data using EBS multi-volume snapshots. These snapshots retain the data from all completed input/output operations, allowing customers to restore their EBS volumes to their exact state at the moment the snapshot was taken.
They’re often used by Amazon customers as part of a backup and disaster recovery plan, and one of the most common use cases is to create a backup of a critical workload, such as a database. Although users can choose to create snapshots of each EBS volume individually, many opt to create a multi-volume snapshot that’s attached to a single Amazon Elastic Compute Cloud Instance.
Previously, if users wanted to create a multi-volume snapshot of their Amazon EBS volumes, but only include some of the volumes attached to a specific instance, it involved making multiple application programming interface calls. With the crash consistent snapshots feature, users can choose the specific volumes they want to exclude when creating the snapshot.
They can do this through a single API call or alternatively through the Amazon EC2 console, Amazon said, achieving substantial cost savings. Crash consistent snapshots for a subset of EBS volumes is also supported by Amazon Data Lifecycle Manager policies, which help to automate the lifecycle of snapshots, the company explained.
The new feature, which was announced at AWS Storage Day, is available now at no added cost, the company said.
Along with more flexible snapshots, AWS announced an upcoming feature called Amazon File Cache that it said is designed to accelerate and simplify hybrid cloud workloads. It provides a high-speed cache on AWS that helps to process file data regardless of where that information is stored. In other words, it serves as a temporary high-performance storage location for data that’s stored in on-premises file servers, in-file servers or object stores in AWS.
According to AWS, Amazon File Cache makes it possible to create dispersed datasets that can be made available to file-based applications on AWS, with a single, unified view at high speeds. These datasets are promised to have submillisecond latency with hundreds of gigabytes of throughput, AWS said. They’re designed to support a variety of cloud “bursting” workloads and hybrid workloads, the company added, such as media rendering and transcoding or electronic design automation.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.