

















 AI
AI
AI
AI
AI
Meta Platforms Inc.’s artificial intelligence research team today announced an updated version of its powerful data2vec algorithm that enables extremely efficient self-supervised learning for vision, speech and text-based AI models.
The original data2vec was launched in January to overcome the limitations of self-supervised learning, which is a technique where machines can learn without relying on labeled training data. The problem it solves is that self-supervised learning algorithms are specialized for a single modality, such as images or text, and require massive amounts of computational power.
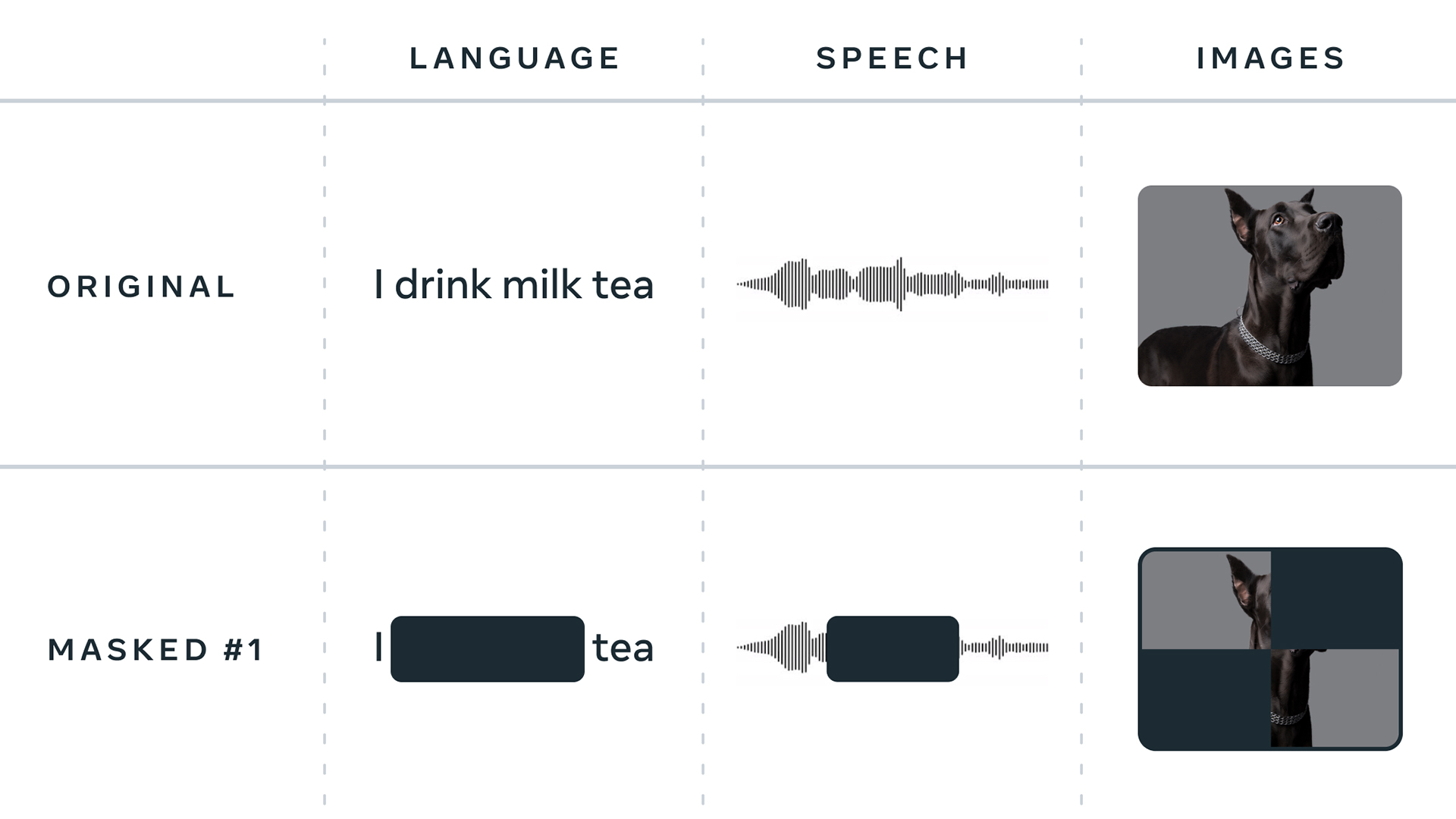
Data2vec enables machines to learn in exactly the same way for three kinds of modalities — speech, vision and text — similar to how humans can learn similarly from different kinds of information, as opposed to using separate learning mechanisms for each modality.
For example, an algorithm that’s used to read text is trained to fill in the blanks in various random sentences. A speech model, however, needs to learn an inventory of basic sounds in order to predict any missing sounds in a person’s speech.
Meanwhile, computer vision models are usually trained to assign similar representations to a color image, of a cow perhaps, and the same image flipped upside down, so it will associate the two more closely than it would with an unrelated image of, say, a dolphin. AI algorithms also predict different units for each modality. Image recognition involves predicting pixels or visual tokens, while text involves words and speech requires models to predict sounds from a learned inventory.
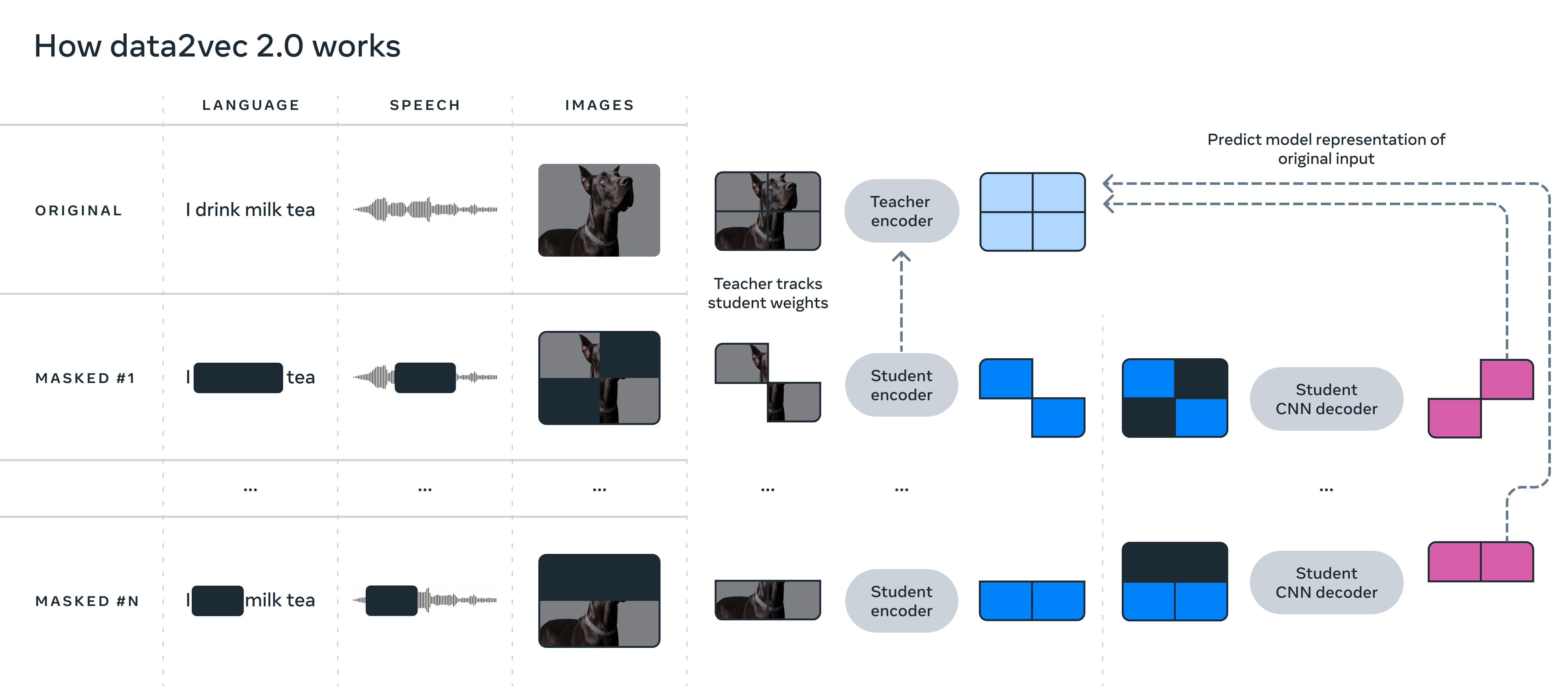
Data2vec overcomes these challenges by teaching AI models to predict their own representations of the input data regardless of what modality it is. By focusing on those representations instead of the usual words, sounds or visual tokens, data2vec can work with multiple types of input data.
With data2vec 2.0, Meta’s researchers claim to have made the algorithm vastly more efficient, while matching its predecessor’s strong performance. It claims that it can achieve the same level of accuracy as the most popular existing algorithm for self-supervised learning in computer vision, but do so 16 times faster.
Data2vec 2.0 improves computational efficiency by predicting contextualized representations of data — essentially the layers of a neural network — rather than predicting the pixels of an image, or the words in a passage of text. It works by contextualizing these target representations, meaning they take the entire training dataset into account to ascertain context. So, it can understand whether or not the word “bank” means a financial institution or the ground next to a river, for example. In this way, data2vec 2.0 can learn much more rapidly than other algorithms, Meta explained.
In order to improve data2vec, Meta said, it has taken target representations for a specific training example and reused them for other masked versions of training examples, where random parts of the example are hidden. Each version is fed into the algorithm, which then predicts the same contextualized target representation.
In this way, data2vec can amortize the computational effort required to create different target representations, Meta said. The algorithm was improved further because it no longer runs its student encoder network for those parts of the training examples that have been blanked out, leading to significant savings on compute cycles. In addition, Meta said, it has introduced a more efficient decoder model that relies on a more efficient multilayer convolutional network, as opposed to a transformer network.
These changes all add up to much greater efficiency, with data2vec 2.0 performing much better than its predecessor on a range of widely used benchmark tests. Its computer vision capabilities were measured on the standard ImageNet-1K image classification benchmark, where it learned to represent images with the same level of accuracy as Masked Autoencoders at up to 16 times faster.
Data2vec 2.0’s performance on the Librispeech speech recognition benchmark matched that of wav2vec 2.0, but was 11 times faster, Meta’s researchers said. Finally, data2vec 2.0 was evaluated on the GLUE natural language understanding benchmark, where it achieved the same level of accuracy as RoBERTa, a reimplementation of BERT, in less than half the time.
Best of all, Meta AI’s researchers said, they’re keen to share the data2vec 2.0 algorithm with the wider AI research community. To that end, the open-source code for data2vec is being made available for anyone to download and use, along with various examples of pretrained models. Meta AI has also published a research paper providing in-depth details on data2vec’s improvements.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





