









 CLOUD
CLOUD
CLOUD
CLOUD
CLOUD
Cloud computing giant Amazon Web Services Inc. kicked off its annual re:Invent 2023 conference this evening with a keynote address where it announced a trio of new capabilities that should make it easier for customers to use its serverless database offerings.
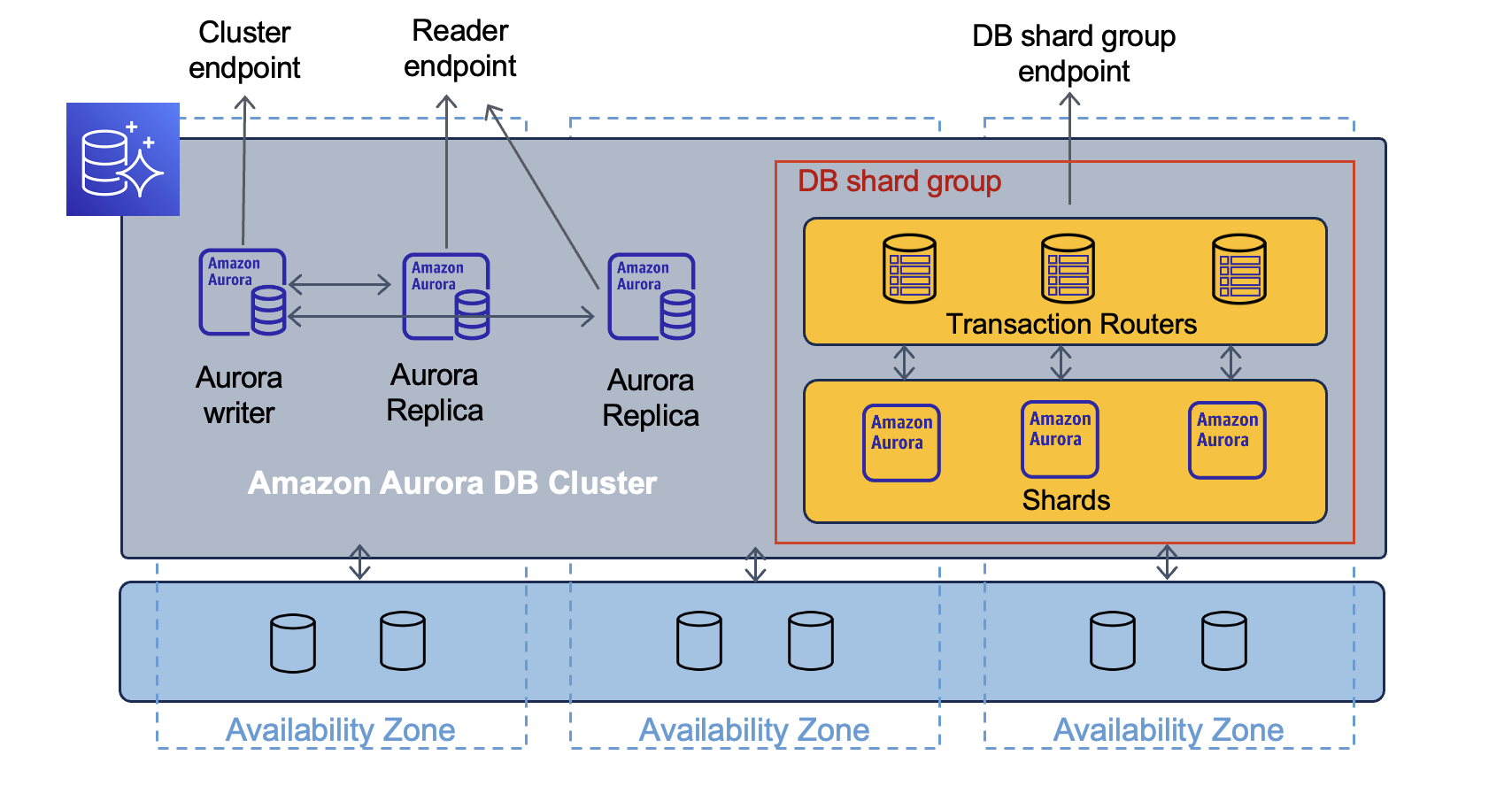
The headline announcement was the introduction of Amazon Aurora Limitless Database, which is a new feature for the Amazon Aurora database that can automatically scale beyond its original write limits, making it much easier for developers to scale their applications. Also announced were new capabilities for Amazon ElastiCache and the Amazon Redshift Serverless database, designed to drive up workload performance while optimizing the platforms to manage costs.
In a keynote speech, Peter DeSantis (pictured), senior vice president of utility computing at AWS, said enterprises today create and store petabytes of information from multiple sources, and require an end-to-end strategy to analyze and manage it at scale. AWS offers a variety of cloud-based big data services to aid in these strategies, he said, including Amazon Aurora, Amazon ElastiCache and Amazon Redshift. With them, customers can avoid much of the heavy lifting involved with running their own data systems manually.
Amazon Aurora is a fully managed MySQL and PostgreSQL database service that can scale to support hundreds of thousands of transactions per second. One of its key capabilities is that it can scale capacity up and down in real time, in fine-grained increments, to provide the optimal amount of resources for each application it powers.
Despite this, DeSantis explained, there are certain applications, such as financial transaction processing and gaming, that need to support hundreds of millions of users globally. Most organizations attempt to do this by scaling horizontally and distributing the workload across multiple smaller database instances.
This process is known as sharding and requires the development of customized software that can shunt requests to the best instance and make changes across multiple instances. Database activity must also be monitored in real time, and it creates an enormous overhead for customers running their own data platforms.
To get around this, AWS today debuted the Amazon Aurora Limitless Database – a new service within Amazon Aurora that is available in preview now. It can scale to millions of write transactions per second and manage tens of petabytes of data.
For customers, all of this is done under the hood, meaning they’re only required to manage what is effectively still a single database. It works by automatically distributing data and queries across multiple Aurora serverless instances based on the user’s underlying data model.
With this, customers no longer need to create customized software to route requests to the appropriate database instances. Instead, the platform does everything automatically, while scaling horizontally or vertically according to the needs of their applications. For engineering teams, maintenance operations are simplified, as any changes can be made just once and applied to multiple database instances, instead of implementing each one manually.
In addition, AWS announced it’s expanding the capabilities of its Amazon ElastiCache service, which is a fully managed Redis and Memcached platform for data caching. The platform is used by applications to store their most frequently accessed data and deliver a big increase in performance and scale.
Although Amazon ElastiCache is useful, organizations need to put a lot of effort into configuring the service and setting it all up first. But some companies want to get started much more quickly without having to design and provision the data cache infrastructure themselves, and this is what the new Amazon ElastiCache Serverless feature, generally available today, is all about.
It enables customers to create a highly available data cache in just a few seconds, without needing to provision or configure anything at all. Because it’s serverless, the entire setup process is fully automated, and the service can automatically replicate data across multiple availability zones with up to 99.99% availability for any workload.
Finally, AWS announced the preview of new artificial intelligence-driven scaling and optimizations for the Amazon Redshift Serverless database to deliver more cost efficiency when running variable workloads.
The latest improvements, available in preview now, are said to deliver “next-generation AI-driven scaling and optimizations,” DeSantis said in the keynote. The new capabilities enable it to perform optimizations on the fly to ensure customers can achieve their specified price/performance targets, he added.
DeSantis explained that Amazon Redshift Serverless can now proactively alter the resources it uses based on workload patterns. During the daytime, it can reduce database capacity at times of low demand, while ramping it up to meet higher demands, such as when a more complex query needs to be processed, he said.
Then at night, it will proactively boost its capacity to support large data processing tasks without any human intervention. It works by automatically measuring and adjusting resources, while carrying out a cost-benefit analysis to ensure it’s optimized for each workload, he added. All the user has to do is define their price-performance target within the AWS console, adjusting the balance between cost and performance.
“The dynamic nature of data makes it perfectly suited to serverless technologies, which is why AWS offers a broad range of serverless database and analytics offerings that help support our customers’ most demanding workloads,” said AWS Vice President of Data and Artificial Intelligence Swami Sivasubramanian. “The new serverless innovations announced today build on this foundation to make it easier for customers to scale to millions of transactions per second, quickly add capacity at a moment’s notice, and dynamically adapt workload patterns to optimize for performance and cost.”
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





