







 INFRA
INFRA
INFRA
INFRA
INFRA
Meta Platforms Inc. today revealed a pair of enormously powerful graphics processing unit clusters that it says will be used to support the training of next-generation generative artificial intelligence models, including the upcoming Llama 3.
Meta engineers Kevin Lee, Adi Gangidi and Mathew Oldham explained in a blog post that the two 24,576-GPU data center scale clusters were built to support much larger and more complex generative AI models than the ones it has previously released, such as Llama 2, a popular open-source algorithm that rivals OpenAI’s ChatGPT and Google LLC’s Gemini. They will also aid in future AI research and development, the engineers said.
Each cluster packs thousands of Nvidia Corp.’s most powerful H100 GPUs, and they are much bigger than the company’s previous large clusters, which contain around 16,000 Nvidia A100 GPUs.
The company has reportedly been busy snapping up thousands of Nvidia’s latest chips, and a report from Omdia recently claimed that the company has become one of the chipmaker’s largest customers. Now we know why.
Meta said it will use the new clusters to fine-tune its existing AI systems and train newer, more powerful ones, including Llama 3, the planned successor to Llama 2. The blog post marks the first time that Meta has confirmed it is working on Llama 3, though it was widely suspected of doing so. The engineers said that Llama 3’s development is currently “ongoing” and didn’t reveal when we might expect it to be announced.
In the longer term, Meta aims to create artificial general intelligence or AGI systems that will be much more humanlike in terms of creativity than existing generative AI models. In the blog post, it said the new clusters will help to scale these ambitions. Additionally, Meta revealed it’s working on evolving its PyTorch AI framework, getting it ready to support much larger numbers of GPUs.
Although the two clusters both have exactly the same number of GPUs interconnected with 400 gigabytes-per-second endpoints, they feature different architectures. One of them features remote direct memory access or RDMA over a converged Ethernet network fabric that’s based on Arista Networks Inc.’s Arista 7800 with Wedge400 and Minipack2 OCP rack switches. The other is built using Nvidia’s own network fabric technology, called Quantum2 InfiniBand.
The clusters were both built using Meta’s open GPU hardware platform, called Grand Teton, which is designed to support large-scale AI workloads. Grand Teton is said to feature four times as much host-to-GPU bandwidth as its predecessor, the Zion-EX platform, twice as much compute and data network bandwidth and twice the power envelope.
Meta said the clusters incorporate its latest Open Rack power and rack infrastructure architecture, which is designed to provide greater flexibility for data center designs. According to the engineers, Open Rack v3 allows for power shelves to be installed anywhere inside the rack, rather than bolting it to the busbar, enabling more flexible configurations.
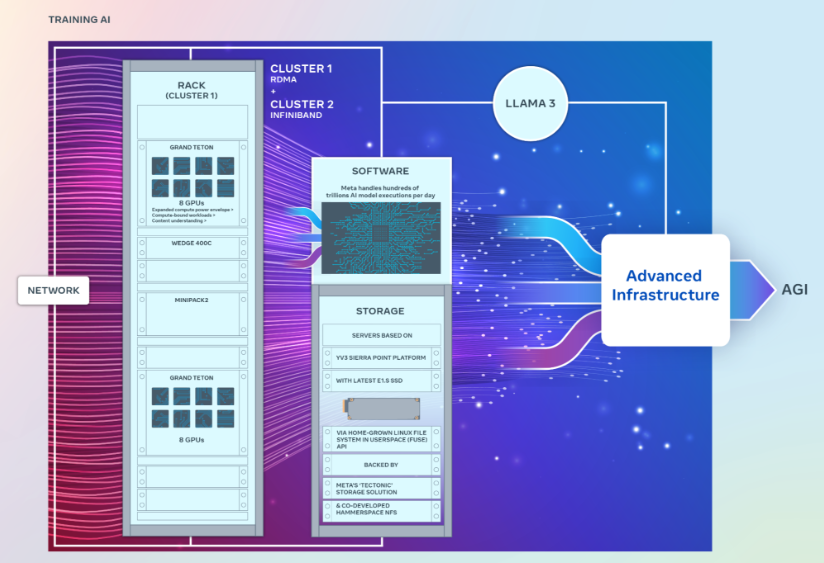
In addition, the number of servers per rack is customizable, enabling a more efficient balance in terms of throughput capacity per server. In turn, that has made it possible to reduce the total rack count somewhat, Meta said.
In terms of storage, the clusters make use of a Linux-based Filesystem in Userspace application programming interface, which is backed up by Meta’s distributed storage platform Tectonic. Meta also partnered with a startup called Hammerspace Inc. to create a new parallel network file system for the clusters.
Finally, the engineers explained that the clusters are based on the YV3 Sierra Point server platform and feature its most advanced E1.S solid-state drives. The team noted that they customized the cluster’s network topology and routing architecture, and deployed Nvidia’s Collective Communications Library of communications routines that are optimized for its GPUs.
Meta mentioned in the blog post that it remains fully committed to open innovation in its AI hardware stack. The engineers reminded readers that the company is a member of the recently announced AI Alliance, which aims to create an open ecosystem that will enhance transparency and trust in AI development and ensure everyone can benefit from its innovations.
“As we look to the future, we recognize that what worked yesterday or today may not be sufficient for tomorrow’s needs,” the engineers wrote. “That’s why we are constantly evaluating and improving every aspect of our infrastructure, from the physical and virtual layers to the software layer and beyond.”
Meta also revealed that it will continue buying up more of Nvidia’s H100 GPUs and intends to have more than 350,000 by the end of the year. These will be used to continue building out its AI infrastructure, and we will likely see even more powerful GPU clusters emerge before too long.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





