







 AI
AI
AI
AI
AI
Researchers from Standford University, University of California Berkeley, Google DeepMind, Massachusetts Institute of Technology and other labs have released OpenVLA, an open-source visual-language-action artificial intelligence model designed for guiding robots based on prompts.
For some time now, researchers have been working toward methods of generalizing a way of having robotics better understand the world using VLAs that can generalize both visual inputs that a camera controlling the robot can see and language understanding for providing tasks from text or audio. This allows the robot to understand a scene and the objects within it and a researcher to describe a task in plain language to have the robot then execute some action.
Most current research into large language models and VLAs for robotics, however, is hampered by closed-source models, which are difficult for researchers to work with and extend. As a result, the production of an open-source model will be a boon for the community.
“OpenVLA sets a new state of the art for generalist robot manipulation policies,” the researchers said in the paper. “It supports controlling multiple robots out of the box and can be quickly adapted to new robot setups via parameter-efficient fine-tuning.”
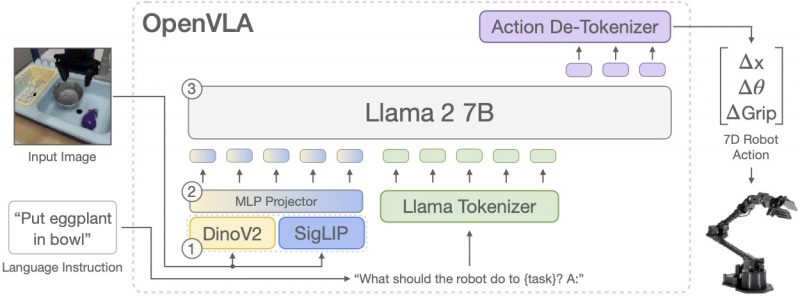
To get started, the team began by training OpenVLA fine-tuning a pre-trained Prismatic-7B VLM, a visually conditioned AI language model for scene understanding and robotic task planning. It was then put together with a visual encoder designed to break down the visual image into embeddings so the underlying AI can understand the scene. The researchers combined that with a Llama 2 7B large language model backbone from Meta Platforms Inc. so users can describe tasks while speaking naturally allowing OpenVLA to turn them into robotic actions.
To train the model, the researchers used a large dataset of more than 970,000 robot manipulation indexes from the OpenX dataset that the team curated specifically for the tasks that they were looking for. The team said that the dataset spans a range of tasks, scenes and robot types such as grippers and arms. The training was done using a cluster of 64 Nvidia A100 GPUs for 15 days.
“OpenVLA is the first open-source VLM-based robotic foundation model trained on large-scale real-world robot manipulation data,” Moo Jin Kim, a Ph.D. student in computer science at Stanford University and co-lead researcher, said on X. “We hope that our model and training frameworks are useful resources to the robot learning community that help advance embodied AI research!”
Right now, the most popular closed-source VLAs on the market include RT-2 and RT-2-X, which also follow a similar pattern of building a dataset of robot actions and combining language understanding and visual scene breakdown. As a result, they can be adapted for AI-driven robotic actions.
To test the new model, the researchers put it through its paces by having it do a variety of tasks such as asking it to pick an object out of a bunch of other objects, move an object, or take an object and place it on another one. All of these tasks are delivered to the robot with a language prompt such as, “Pick up the carrot,” or “Place the carrot on the orange plate,” to see if the VLA is capable of replicating the command.
According to the researchers, OpenVLA robustly outperformed RT-2-X, which is 55B parameters, across two different testing setups using the WindowX setup from Bridge V2 and the Google Robot embodiment series.
As an open-source model, the release code for OpenVLA is publicly available on GitHub and the model checkpoints are available on HuggingFace.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





