AI
AI
AI
AI
AI
OpenAI introduced a set of new developer tools today at its DevDay product event in San Francisco.
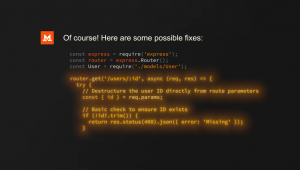
The additions are headlined by Realtime API, a cloud service that enables software teams to equip their applications with multimodal processing capabilities. The service powers those capabilities using OpenAI’s artificial intelligence models. On launch, Realtime API supports one use case: creating AI applications that can understand voice commands and read out their responses out loud.
Usually, sending a voice command to an OpenAI model for processing involves multiple steps. Developers have to transcribe the audio, feed the transcript into the model and then turn the model’s text-based output into synthetic speech. OpenAI’s new Realtime API makes it possible to stream audio to GPT-4o directly without those intermediary steps.
The company says that the service can not only simplify development but also reduce model latency. As a result, AI applications powered by Realtime API can respond to user instructions more quickly. Moreover, the service includes a feature that allows the applications it powers to automatically perform tasks in external systems.
In the future, OpenAI plans to extend Realtime API to several additional use cases including image and video processing. To make it easier for software teams to adopt the service, the company will also make changes to its development kits. Those changes will simplify the task of integrating Realtime API into workloads built using Python and the Node.js application development framework.
Realtime API is not the only multimodal processing tool that OpenAI detailed at DevDay. It also introduced a similar capability for processing voice input to its existing Chat Completions API. According to OpenAI, the capability is geared toward audio processing use cases that don’t require the low latency offered by Realtime API.
For developers building applications that process images, OpenAI is rolling out a feature called vision fine-tuning. Fine-tuning is the process of supplying a neural network with additional training data to boost the quality of its output. Using the new vision fine-tuning capability, developers can provide ChatGPT-4o with custom image datasets to make it better at computer vision tasks.
A company using GPT-4o to generate website layouts could provide the model with a collection of sample designs. Similarly, organizations that rely on the model to extract data from scanned documents could reduce accuracy issues training it on previously processed files. OpenAI says that a fine-tuning database requires as few as 100 images to improve GPT-4o’s performance.
Alongside the new multimodal capabilities, OpenAI today debuted two features designed to lower inference costs for customers. The first addition, Model Distillation, produces savings through an AI method known as knowledge distillation. This method allows developers to replace a large, highly capable model with a smaller one that uses less hardware and consequently costs less.
Given the same prompt, a large neural network is likely to generate a better response than a smaller one. With knowledge distillation, developers can take the larger model’s higher-quality response and feed it into the smaller model. This allows the latter algorithm to match the output quality of its more advanced counterpart using a small fraction of the hardware.
OpenAI’s new model distillation feature is available through an application programming interface. It enables developers to submit prompts to one of the company’s frontier models and then turn the model’s responses in an AI training dataset. That dataset, in turn, can be used to boost the quality of a smaller neural network.
The other feature OpenAI rolled out today to lower customers’ inference costs is called Prompt Caching. It allows the company’s models to reuse user input in certain situations and thereby avoid repeating calculations that they already completed once before. OpenAI is promising an up to 50% reduction in inference costs as well as better response times.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.