









 AI
AI
AI
AI
AI
LastMile AI Inc., creator of a developer platform for customizing and debugging artificial intelligence applications, today announced the launch of what it says is the industry’s first fine-tuning platform for evaluator models.
Called AutoEval, it’s all about solving the “last mile” problem of evaluating complex AI applications to ensure they can achieve maximum efficiency and accuracy. LastMile AI defines the “last mile” problem of generative AI as the lack of evaluation metrics that can measure the performance of new applications.
The challenge with this is that every generative AI app is different, designed to perform a very specific task, which means it must be evaluated using equally specific criteria. According to the startup, the lack of proper evaluation tools is one of the main reasons why very few generative AI apps have reached full production, because enterprises have no way to ensure they’re accurate, safe and reliable.
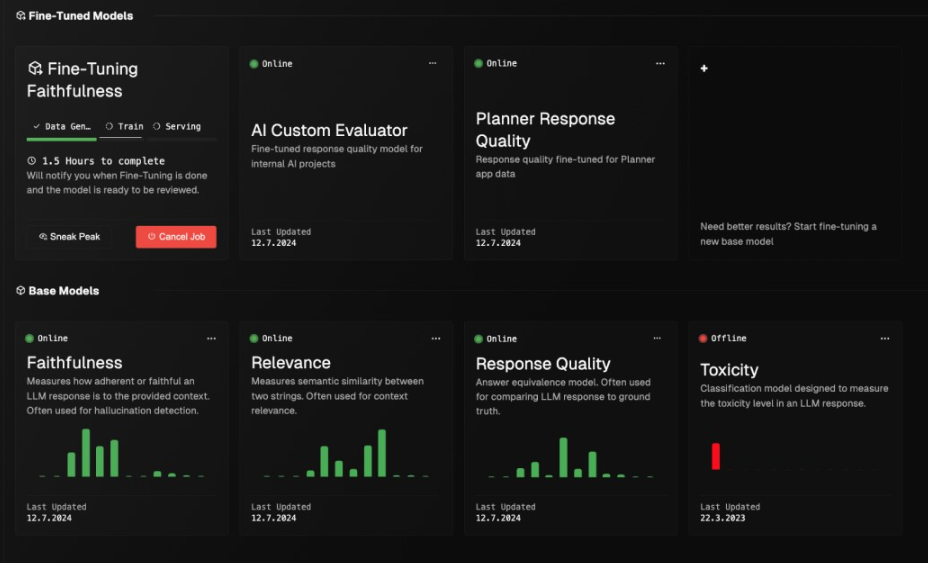
This is the issue the startup claims to be solving with AutoEval. Basically, with AutoEval, companies can quickly create highly customizable “evaluator models” to test the capabilities of their generative AI applications.
It provides a number of novel capabilities that can help enterprises to properly assess new AI applications, the startup says, with one of the most crucial ones being its ability to generate synthetic data labels that are used to train them. The idea is that synthetic label generation can be used to augment an application’s original training dataset, reducing the time it needs for a subject matter expert to curate additional training data.
In addition, AutoEval introduces a small language model called alBERTa as an evaluator for AI applications. It’s trained to assess common metrics for large language models and retrieval-augmented generation or RAG techniques, such as relevance, answer equivalence, faithfulness, toxicity and summarization, and it can be adapted to test for more specific outputs, too. The insights from these evaluations will help enterprises to know if their AI applications are safe to deploy or if more work is needed.
Using AutoEval, developers can adopt an “Eval-Driven Development” approach to evaluating their AI models, which is a process that involves first establishing the evaluation criteria. Then they can measure the model’s baseline performance before finally taking steps to improve the app, based on the initial evaluation metrics. It’s an approach that mirrors the test-driven development processes used in traditional software development cycles, LastMile AI said.
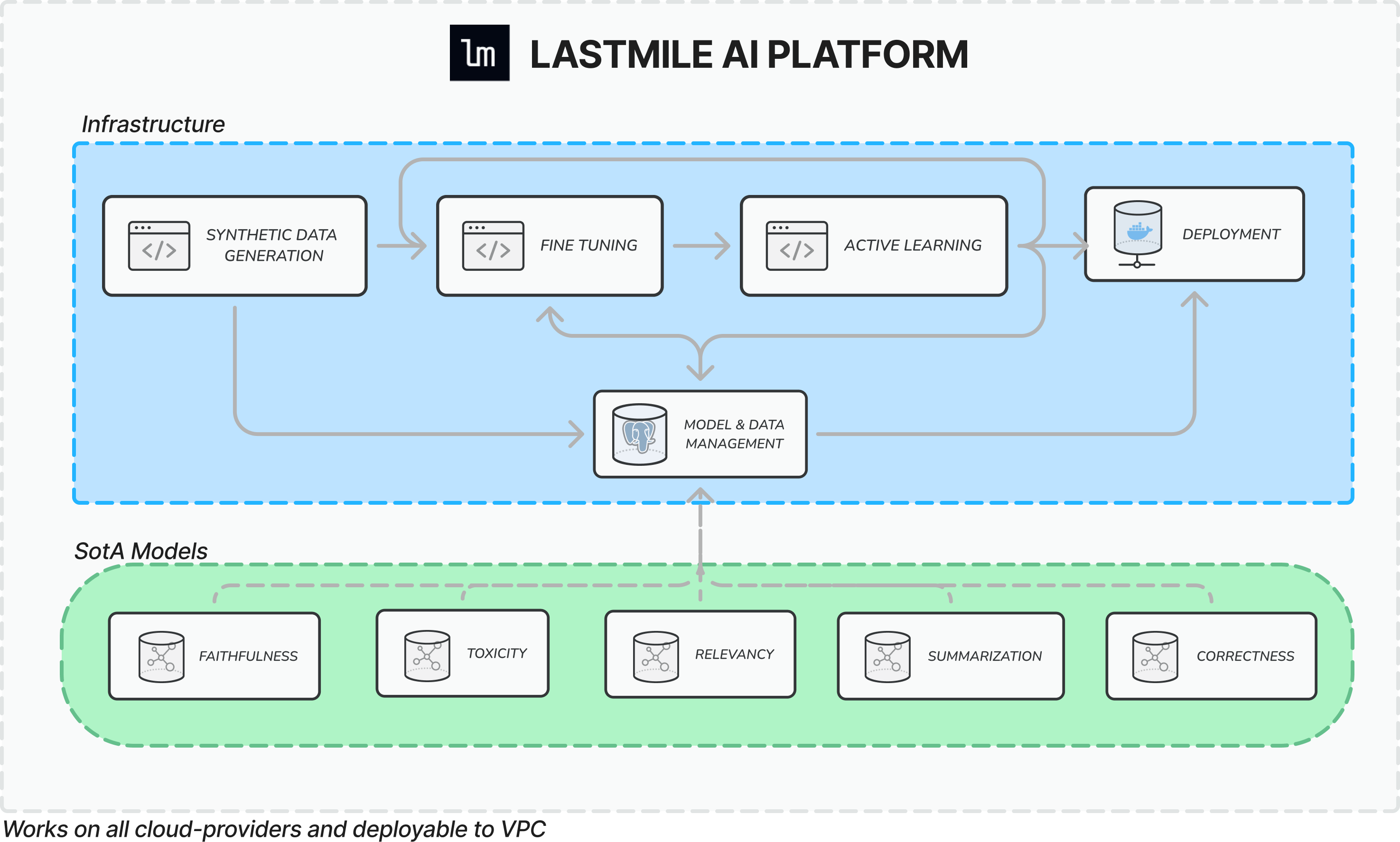
Perhaps the best thing about AutoEval is that its platform is extremely lightweight, and can run on much more affordable central processing units instead of graphics processing unit-based servers. Even on CPUs, it can process inference requests in less than 300 milliseconds, the startup said, acting as a real-time guardrail for any LLM.
LastMile AI said it has big plans for AutoEval. It can already be accessed via the company’s website for virtual private cloud deployments, and it will launch on major public cloud marketplaces in the coming weeks.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





