 CLOUD
CLOUD
CLOUD
CLOUD








CLOUD
Streaming data software provider Confluent Inc. today announced new artificial intelligence and analytics capabilities designed to simplify real-time data processing and enterprise intelligence.
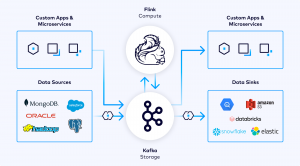
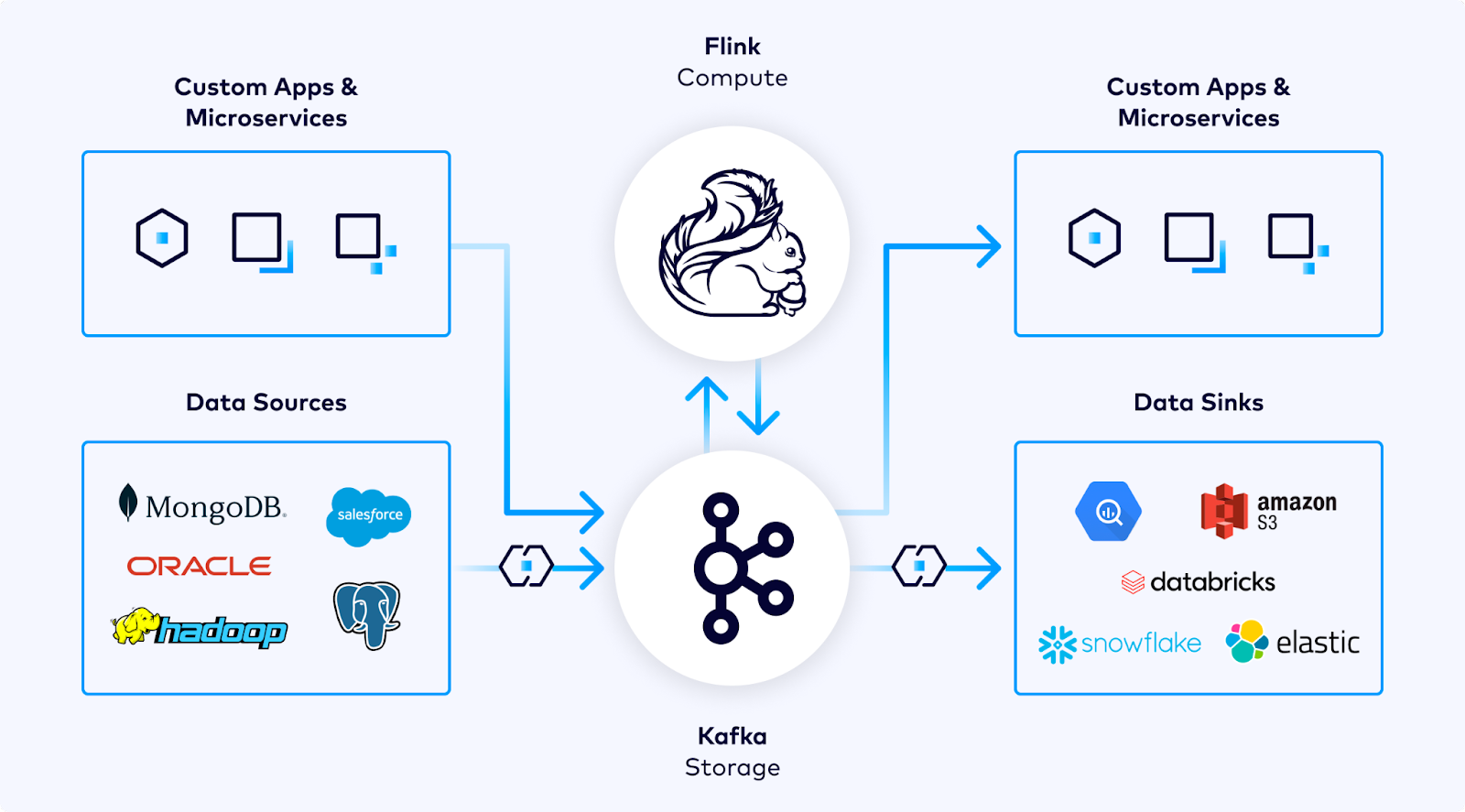
The announcements include updates to Confluent Cloud for Apache Flink that introduce what it says is seamless AI model inference, vector search and built-in machine learning functions. Meanwhile, enhancements to Tableflow improve access to operational data in real-time analytics environments, with expanded support for Apache Iceberg and Delta Lake.
The new updates in Confluent Cloud for Apache Flink are designed to streamline and simplify the process of developing real-time AI applications. The service now supports Flink Native Inference, which cuts through complex workflows by allowing teams to run any open-source AI model directly in Confluent Cloud.
A new Flink search feature unifies data access across multiple vector databases to streamline discovery and retrieval within a single interface and new built-in machine learning functions bring AI-driven use cases, such as forecasting and anomaly detection, directly into Flink SQL.
Confluent is pitching the innovations as redefining how businesses can harness AI for real-time customer engagement and decision-making.
“Building real-time AI applications has been too complex for too long, requiring a maze of tools and deep expertise just to get started,” explains Shaun Clowes, chief product officer at Confluent. “With the latest advancements in Confluent Cloud for Apache Flink, we’re breaking down those barriers — bringing AI-powered streaming intelligence within reach of any team.”
Alongside the Confluent Cloud for Apache Flink’s new features, Confluent also announced advances in Tableflow, the company’s data integration solution that enables real-time access to operational data in open table formats for advanced analytics and AI applications.
The latest update makes Apache Iceberg support generally available, allowing teams to instantly transform Apache Kafka topics into Iceberg tables for integration with data warehouses and analytics engines. The service eliminates the need for complex preprocessing, reducing operational overhead and ensuring a consistent, real-time source of truth for AI-driven applications.
Confluent also launched an early access program for Delta Lake, expanding Tableflow’s compatibility with Databricks’ open-format storage layer. The integration enables faster decision-making and more efficient AI workflows by maintaining a unified view of real-time data across operational and analytical applications,
Additional enhancements include bring your own storage options and deeper integrations with catalog providers like AWS Glue and Snowflake Open Catalog, which give enterprises greater flexibility and governance control over their data.
“With Tableflow, we’re bringing our expertise of connecting operational data to the analytical world,” said Clowes. “Now, data scientists and data engineers have access to a single, real-time source of truth across the enterprise, making it possible to build and scale the next generation of AI-driven applications.”
THANK YOU