







 AI
AI
AI
AI
AI
Artificial intelligence chip startup Cerebras Systems Inc. is heralding the launch of Qwen3-32B, one of the most advanced and powerful open-weight large language models in the world, as proof of its ability to outcompete Nvidia Corp. in AI inference.
The company said its inference platform has achieved the previously impossible — enabling advanced AI reasoning to be performed in less than two seconds, or essentially in real time.
The Qwen3-32B model is available now on the Cerebras Inference Platform, a cloud-based service that the company claims is able to run powerful LLMs at many times faster than comparable offerings based on Nvidia’s graphics processing units.
Cerebras is the creator of a specialized, high-performance computing architecture that runs on dinner plate-sized silicon wafers. Its flagship offering is the Cerebras WSE-3 processor that launched in March 2024, based on a five-nanometer process and featuring 1.4 trillion transistors. It provides more than 900,000 compute cores, meaning it has 52 times more than the number of cores found on a single Nvidia H100 GPU.
The WSE-3 processor also features 44 gigabytes of onboard static random-access memory, solving the major bottleneck associated with Nvidia’s chips – the need for greater memory bandwidth.
Cerebras launched its AI inference service last August. Inference refers to the process of running live data through a trained AI model to make a prediction or solve a task, and high performance is becoming essential to the AI industry as more models and applications move into production.
The company claims that its inference platform is the best in the world, capable of running the most powerful AI models at speeds of more than 2,000 tokens per second, essentially leaving Nvidia-based inference services in the dust. It has previously said that its platform enables Meta Platforms Inc.’s Llama 4 run up to 20 times faster than usual, and makes similar claims about many other top-tier AI models.
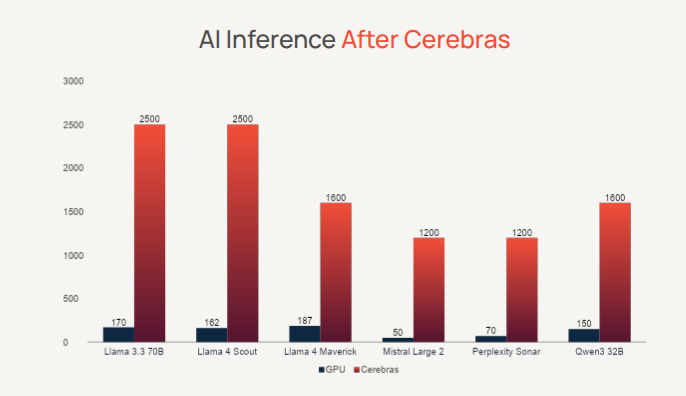
Such claims are given credence by a growing list of enterprise customers, including AI model makers such as Mistral AI, and the AI-powered search engine Perplexity AI Inc.
With the launch of Qwen3-32B, Cerebras co-founder and Chief Executive Andrew Feldman says the company’s inference platform is fast enough to “reshape how real-time AI gets built.”
“This is the first time a world-class reasoning model – on par with DeepSeek R1 and OpenAI’s o-series — can return answers instantly,” he said.
Qwen3-32B is one of the most advanced open-weights reasoning models ever created. It was developed by the Chinese cloud computing giant Alibaba Group Holding Ltd., and has shown on benchmarks that it can match the performance of leading closed models such as GPT-4.1 and DeepSeek R1.
When running on the Cerebras Inference Platform, the Qwen3-32B model can perform sophisticated reasoning and generate a response in as little as 1.2 seconds, Cerebras said. That’s more than 60 times faster than the best competing models, including OpenAI’s o3.
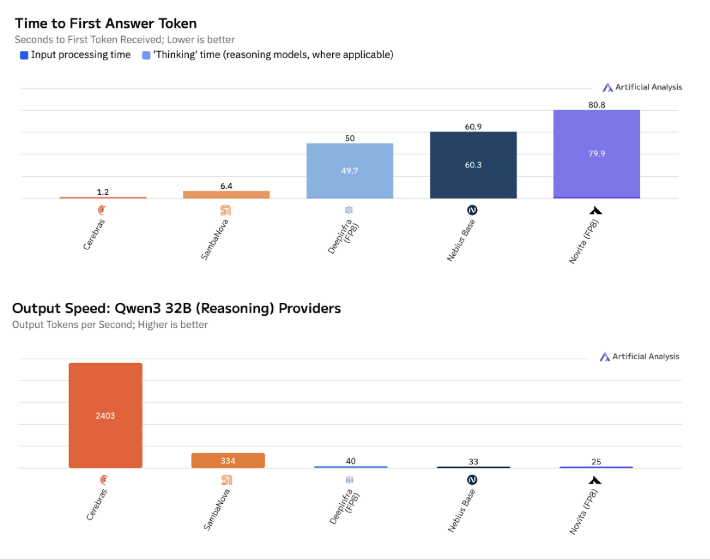
The availability of Qwen3-32B on the Cerebras platform paves the way for a new generation of much more responsive AI agents, copilots and automation workloads, the company said. Reasoning models are the most powerful kinds of LLMs, capable of using multistep logic to guide structured decision-making and the use of third-party software tools. They have enormous potential, but they have always struggled with latency, requiring anywhere from 30 to 90 seconds to generate outputs. This latency has always limited their usefulness – until now, Cerebras says.
Holger Mueller of Constellation Research Inc. said Cerebras’ inference capabilities are a key development, because reasoning models are essential for the AI industry to be able to achieve its end goal of artificial general intelligence, or AGI, which surpasses the capabilities of humans.
“Cerebras shows us that specialized hardware can make models reason faster and more efficiently,” the analyst said. “Using Qwen3-32B as a benchmark is a good showcase for its performance achievements, but it remains to be seen how much of a dent it will make in Nvidia’s market. In the past, specialized platforms have always found their niche, but the size of it will depend on price, availability and the willingness of enterprises to engage with them, rather than generalized platforms.”
That likely explains why Cerebras is offering rapid access to Qwen3-32B at very some very reasonable prices, starting at just 40 cents per million input tokens, and 80 cents per million output tokens. According to Feldman, that makes it about 10 times cheaper than OpenAI’s GPT-4.1 model.
“Here we are with an open-source model that’s better than, or equal to, the best models in the world in most metrics,” Feldman said. “And we’re serving it for pennies on the dollar.”
Cerebras is doing its best to encourage developers to give it a go, saying that everybody will receive 1 million free tokens per day to start experimenting, with no waitlist. Because Qwen3-32B is Apache 2.0 licensed, it’s entirely free to use, and can be integrated into applications using OpenAI- and Claude-compatible endpoints, the company said.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





