

















 AI
AI
AI
AI
AI
Google LLC wants to combine the emerging “agentic” capabilities of its Gemini artificial intelligence assistant with advances in areas such as robotics and physics to create a new kind of “world model” that can imagine things in the same way as humans can.
That vision of a universal AI assistant that can make plans by simulating aspects of the world was outlined today by Google DeepMind Chief Executive Demis Hassabis during Google I/O 2025. It was the backdrop for a flurry of new features for the company’s Gemini large language models, including its flagship Gemini 2.5 Pro as well as upgrades to its Veo and Imagen video and image creation models.
The world model, Hassabis said, is the culmination of years of research. It spans Google’s work on training AI agents to defeat humans in games such as Go and StarCraft, to Genie 2, a revolutionary new model that can create interactive 3D environments from a combination of text and image prompts.
Google has talked about world models before, and has already done lots of groundwork, with Gemini demonstrating the ability to use its knowledge of the world to reason and make decisions. Other examples of this include Gemini Robotics, which is a neural network that paves the way for robots to go beyond following instructions, and make their own decisions on the fly.
“Making Gemini a world model is a critical step towards developing a new, more general and useful kind of AI,” Hassabis said. “A universal AI assistant… that’s intelligent, understands the context you are in, that can plan and take action on your behalf, across any device.”
Google ultimately sees Gemini evolving into a universal AI assistant that’s able to make everyone more productive by performing mundane, everyday tasks on their behalf and providing useful recommendations that will enrich their lives. To get there, Gemini will require a much broader range of skills, including the ability to watch and understand videos and remember things, and Google is already building these capabilities. They can be seen in Gemini Live, a feature within Gemini that enables users to have real-time conversations with the chatbot while sharing their camera or screen, in order to provide it with more context.
These capabilities will also be integrated with new search experiences and form factors, such as glasses, Hassabis said. At the same time, Google has been exploring how Gemini’s agentic AI skills can help people to multitask more effectively.
With Project Mariner, the company is exploring the future of human-agent interactions, beginning with the web browser. It has developed a system of AI agents that can perform up to 10 tasks simultaneously, helping users buy items online, book hotels, perform research, pull up the latest news headlines and so on.

Hassabis said the latest version of Project Mariner is being made available to Google AI Ultra subscribers in the U.S. And its computer use skills are being integrated with the Gemini application programming interface, bringing it much closer to its vision of a universal AI assistant.
Google AI Ultra is a new subscription offering that aims to give users higher limits and access to the most advanced features available. Announced today, it’s aimed at filmmakers, developers, creatives and professionals, as well as consumers who just want to access the absolute best that Google has to offer.
As a premium service, it comes with a premium price tag of $249.99 per month, though users who move fast can take advantage of a special 50% discount for the first three months. It’s currently available only to U.S. customers, but an expansion is promised soon.
As Hassabis was busy talking about his vision, Google unleashed a wave of new features in Gemini 2.5 Pro, its most advanced large language model to date.
The updates are mostly focused on improving Gemini 2.5’s performance, which are reflected in the model’s latest results on a series of key benchmarks, Google DeepMind Chief Technology Officer Koray Kavukcuoglu said in a blog post.
Following a number of tweaks made under the hood, Gemini 2.5 has emerged as the best performing model on the popular coding leaderboard WebDev Arena, achieving a record-breaking ELO score of 1420, Google said. It’s also the leader across all major categories on a second leaderboard known as LMArea, which evaluates models according to human preference across multiple domains.
In addition to the performance enhancements, Gemini 2.5 Pro is getting an experimental new reasoning mode called Deep Think, which leverages new research techniques that allow it to carefully consider a hypothesis before responding.
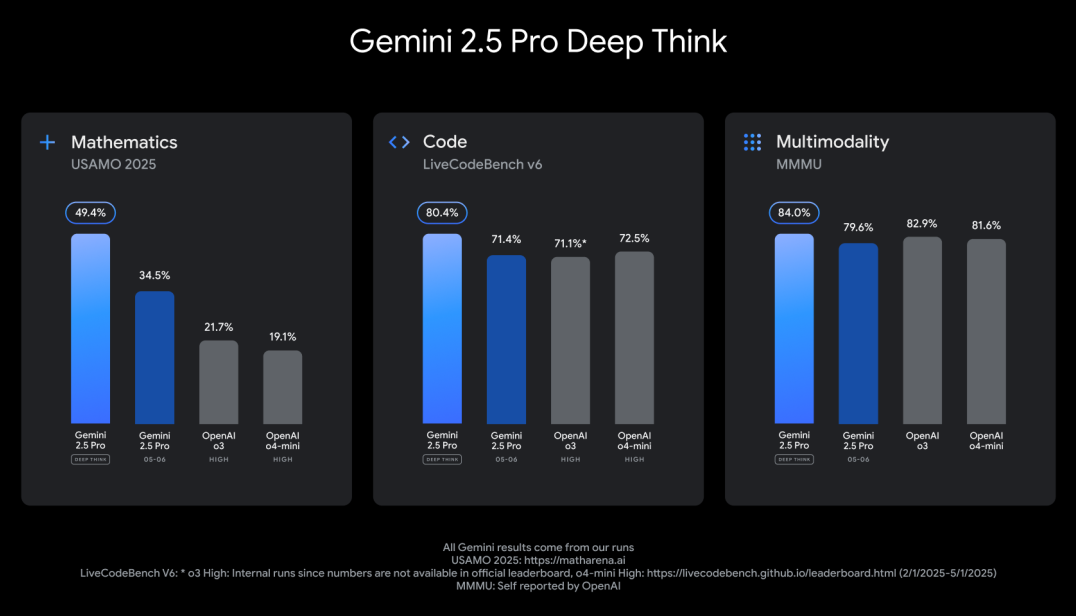
According to Kavukcuoglu, 2.5 Pro Deep Think achieved an impressive score on the 2025 USAMO math benchmark, which is considered to be one of the toughest in the business. It also racked up a score of 84% on the MMMU benchmark for multimodal reasoning. For now, the new Deep Think mode is only being made available to trusted testers, as Google continues to evaluate the feature for safety.
Elsewhere, Google has also beefed up the performance of Gemini 2.5 Flash, a more efficient version of Gemini 2.5 Pro that’s optimized for low-power devices. The lightweight model shows improved scores across multiple benchmarks spanning code, long context, reasoning and multimodality, as well as greater efficiency, using an average of 20% to 30% less tokens in its outputs.
Google revealed a string of developer-focused upgrades too. They’re getting a preview of audio-visual inputs and native audio out dialogue in the Live API. It’s an update that’s aimed at developers looking to integrate more natural conversational experiences directly within their applications, allowing for more control over tones, accents and speaking styles, Google said.
Developers will also be able to take advantage of new “thought summaries” for Gemini 2.5 Pro and 2.5 Flash in the Gemini API and Vertex AI platforms, which are meant to surface the model’s key thoughts in response to a question. It’s all about providing more clarity on how they work, with information about model actions, such as when they decide to use a specific tool, Google said.
Finally, Google is adding support for the fast-growing Model Context Protocol in the Gemini API to enable easier integration with third-party tools. MCP is an open-source protocol first developed by Anthropic PBC, providing a standardized way for AI models to interact with other software. Although only launched this year, MCP has attracted enormous support from the AI community, and Google’s embrace comes just a day after Microsoft made a similar announcement.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





