AI
AI
AI
AI
AI
Artificial intelligence infrastructure startup Majestic Labs Inc. launched today with $100 million in initial funding.
The company raised the bulk of the capital, $71 million, through a Series A round led by Bow Wave Capital. Lux Capital led Majestic Labs’ earlier seed investment. The hardware maker is also backed by SBI, Upfront, Grove Ventures, Hetz Ventures, QP Ventures, Aidenlair Global and TAL Ventures.
Majestic Labs is led by chip engineering executives Ofer Schacham, Masumi Reynders and Sha Rabii. Schacham, the company’s chief executive, earlier led the Google LLC team that develops chips for the search giant’s consumer devices. Reynders and Rabii also held senior roles in the Alphabet Inc. unit’s semiconductor group.
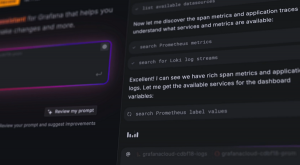
Large language models generate a significant volume of temporary data while processing prompts. As a result, they have to be deployed on servers with a large memory pool that can accommodate their data. Moreover, LLMs require the ability to move data between a server’s memory pool and graphics cards at high speed.
Increasing an AI cluster’s memory capacity often requires companies to add servers, which in turn necessitates deploying more supporting equipment such as cooling systems. That significantly increases hardware costs. Majestic Labs is tackling the challenge with a server that it says will include as much memory as 10 racks. A server requires a small fraction of the cooling equipment as a rack, which decreases procurement costs and power usage.
Majestic Labs says that its system contains a “custom accelerator” chip and a likewise internally developed memory interface module. The server can be equipped with up to 128 terabytes of RAM. Majestic Labs didn’t specify what variety of RAM its system contains but described the technology as “extremely fast, power-efficient, high-bandwidth memory,” which hints it might be using HBM memory. HBM is a particularly high-performance type of RAM that is ubiquitous in AI clusters.
A standard RAM chip comprises a single layer of memory cells. An HBM module, in turn, contains upwards of a dozen memory cell layers that are stacked atop one another. The layers are linked together by millions of microscopic, copper-filled electric wires called through-silicon vias.
Increasing the amount of memory in an AI cluster’s servers can boost LLM performance. However, the size of the performance gain varies based on the inference task that the model performs. The computations an LLM carries between the moment a user enters a prompt and the first output token are more influenced by graphics card performance than memory speed. In contrast, the calculations that are used to generate subsequent output tokens can be significantly accelerated by adding more memory to an AI cluster.
Majestic Labs’ server can not only run inference workloads but also train new LLMs. “Our systems support vastly more users per server and shorten training time, lifting AI workloads to new heights both on-premises and in the cloud,” Rabii said.
CNBC reported that Majestic Labs plans to sell its hardware to hyperscale data center operators, financial institutions and pharmaceutical companies. The startup plans to ship its first servers in 2027. In the meantime, it will work to grow its engineering team, enhance the software stack that ships with its server and raise additional funding.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.