AI
AI
AI
AI
AI
Google LLC’s DeepMind artificial intelligence unit today rolled out a new text-to-speech model called Gemini 3.1 Flash TTS.
Unlike its earlier, robotic predecessors, it enables users to direct the vocal style, delivery and pace of chatbot responses through text-based commands, the company said in a blog post. A video posted on X shows that Gemini 3.1 Flash TTS provides advanced options for controlling the voice projected by the model, with controls that can adapt its inflection and tone. Options include “enthusiastic,” “positive surprise” and “informative.”
In addition, the model also allows users to select different regional accents of various major languages. English has a myriad of options to choose from, including American “Valley” and “Southern” accents, plus numerous British variants, including “Brixton” and “RP.” There are other accents too, such as “Transatlantic.”
Another feature is Gemini 3.1 Flash TTS’s director-level controls, which allow users to adjust the model’s speaking style and pace. There are also format templates that users can choose from, including podcast conversation, audiobook narrator, language tutor, voice assistant, wellness guide, news broadcaster and support agent styles. Google said users will be able to “set the stage” by defining the environment and providing specific dialogue instructions, and that they’ll be able to export these settings as application programming interface code.
Gemini 3.1 Flash TTS is our most controllable text-to-speech model yet.
With new Audio Tags, you can easily direct vocal style, delivery, and pace through text commands. 🧵 pic.twitter.com/Bq4SD8eLUN
— Google DeepMind (@GoogleDeepMind) April 15, 2026
“This world-building context helps characters remain “in-character” and react to one another naturally across multiple turns,” the company said in a blog post. “Once the performance is perfected, these exact parameters can be exported as Gemini API code to ensure consistent, recognizable voices across various projects and platforms.”
Google said the goal of Gemini 3.1 Flash TTS is to offer more natural-sounding speech experiences, and it’s doing this in a huge variety of more than 70 languages, including Japanese, Hindi and German. The model also features SynthID watermarks on all of its outputs, so its content is easy to detect.
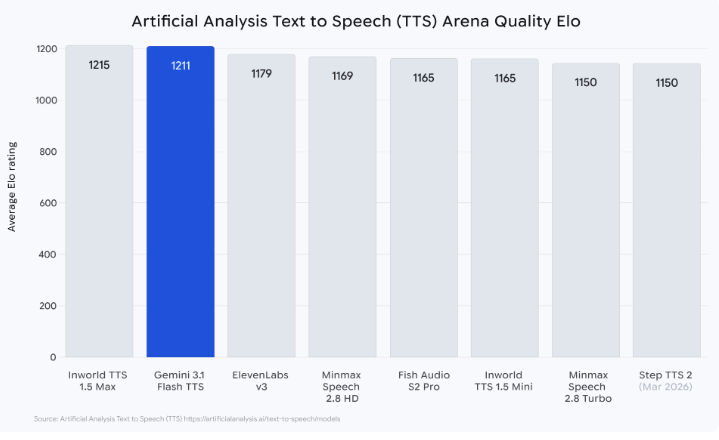
On the Artificial Analysis TTS leaderboard, a benchmark that captures thousands of blind human preferences, Gemini 3.1 Flash TTS ranked second overall with a score of 1211, surpassing many other popular text-to-speech models.
The model is available for developers to access now via the Gemini API and Google AI Studio, and for enterprises through the Vertex AI platform. Everyone else can play around with it at Google Vids.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.