













 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
Aiven Ltd., a startup that’s focused on delivering cloud-hosted and managed versions of the most popular open-source software platforms, has announced the general availability of its latest offering, Aiven for Apache Flink.
With the new offering, businesses can now access a fully managed version of the real-time data stream processing platform on Amazon Web Services, Google Cloud and Microsoft Azure. Aiven provides managed services for open-source software including the Apache Cassandra, InfluxDB, MySQL and PostgreSQL databases, plus the Apache Kafka event streaming platform, Elasticsearch and more.
Apache Flink is the newest addition to its catalog of offerings. It’s a big-data processing framework that’s often used in real-time applications in industries such as video streaming, e-commerce and financial services. It enables data to be processed as it’s created, and can be used to power data analytics, transaction processing and artificial intelligence workloads in real time.
Apache Flink is often compared to Apache Spark, but the main difference is that it can compute data in motion, as it’s being processed, resulting in true real-time data processing. In contrast, Apache Spark processes information in small chunks, using a technique known as “microbatching” that requires data to be accumulated in very small batches before computing it.
With Aiven for Apache Flink, users will benefit from a redesigned Flink Structured Query Language interface that Aiven says makes it easier for developers to build unified, robust and scalable event-driven applications and streaming analytics tools. It allows for faster data pipeline prototyping, validation and deployment, meaning developers can bring new applications to market much more quickly, the company said.
Of course, companies will also benefit from the lack of operational overheads. Because Aiven for Apache Flink is a fully managed service, developers no longer need to concern themselves with tasks such as clusters up and down, since all of these management tasks are automated.
Aiven said the ability to analyze data in real time is rapidly becoming a “must-have” for enterprises because it enables them to provide richer contextual experiences to customers and end users. To that end, Aiven for Apache Flink is said to closely integrate with Aiven for Apache Kafka, a distributed, fault-tolerant, high-throughput pub-sub messaging system that’s used to store event data – the information that’s generated by applications as they’re being used. Kafka provides a way to store these streams of data and direct them to downstream repositories such as data lakes and data warehouses, where they can be analyzed.
By offering both Apache Flink and Apache Kafka, Aiven says it can now offer a more robust and scalable, production-grade streaming infrastructure to support every kind of real-time data application scenario companies will face.
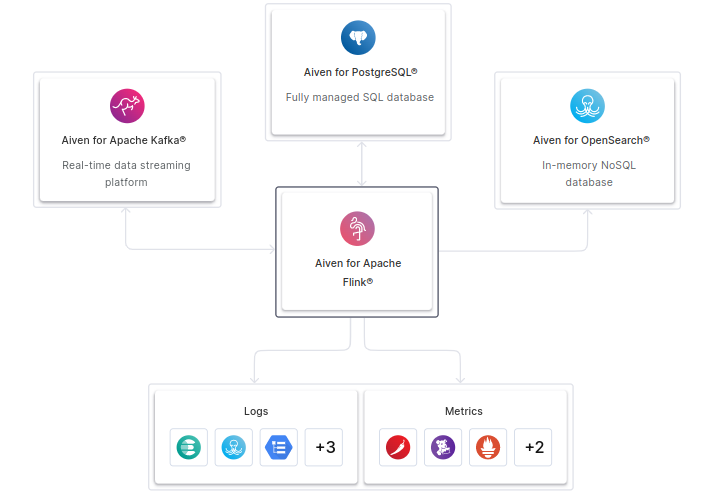
“Aiven for Apache Flink is the glue and intelligence tying together our platform capabilities between Apache Kafka along with popular databases such as PostgreSQL, OpenSearch, and more integrations coming every week,” said Aiven Vice President of Product Management Jonah Kowall. “Our experience brings a cloud streaming data infrastructure that is resilient, scalable and can be easily migrated and managed across cloud vendors through the Aiven console.”
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





