AI
AI
AI
AI
AI
Thinking Machines Lab Inc., the artificial intelligence research startup founded by former OpenAI Group PBC Chief Technology Officer Mira Murati, wants to move beyond the era of “turn-based” AI interactions.
The company has just announced a research preview of its first “interaction models,” which are a new class of multimodal AI systems designed to avoid the inevitable pauses that characterize human interactions with AI systems. As anyone who uses AI regularly knows, the basic interaction is a spotty one, at best: The user provides an input, such as text or an image upload, then waits anywhere from a few milliseconds to several minutes, depending on the model used, before finally receiving the output.
This occurs because existing models need to wait for their users to finish asking a question or complete the sentence they’re saying before they can start processing a response. To get around this, Thinking Machines has created an entirely new model architecture that enables “full-duplex” communication, which means AI that can listen, see and talk simultaneously.
Thinking Machines argues that the back-and-forth interactions with current models forces human users to “contort themselves” to the interface. Over multiple months of use, humans have learned to phrase their questions like emails and batch their thoughts, because they know the AI they’re using cannot handle interruptions or deal with the subtle “backchanneling,” or the “mhmms” and “I sees” that exist in truly natural human interactions. But if AI is to become a true humanlike collaborator in high-stakes applications like medical surgery, it has to find a way to ditch that lag.
The company’s answer is a new model architecture that drops the standard alternating token sequence in favor of a larger, multistream micro-turn-based design. The way it works is that the system processes inputs and outputs in tiny 200-millisecond chunks, enabling it to react in real time to any visual or auditory cues it picks up on, even when it’s already speaking. The startup says this “dual-model” architecture is designed to balance speed with deep reasoning.
The first component of this new architecture is TML-Interaction-Small, a 276-billion parameter mixture-of-experts model that’s designed to manage dialogue, presence and immediate follow-ups with rapid speed. It’s paired with an asynchronous agent that’s meant to work behind the scenes, so while the Interaction Model keeps the conversation flowing, the Background Model takes care of all of the heavy lifting – the complex reasoning, web searches and tool calls required to get things done or work things out. It can then send its findings to the Interaction Model when it’s ready, and these will be woven into the live chat.
In a blog post, the company explained that instead of using heavy external encoders to translate audio or video into signals the model can understand, it utilizes “encoder-free early fusion” that takes in raw signals directly through a lightweight embedding layer. Everything is processed rapidly within the transformer, which is what gives it such an advantage in terms of latency.
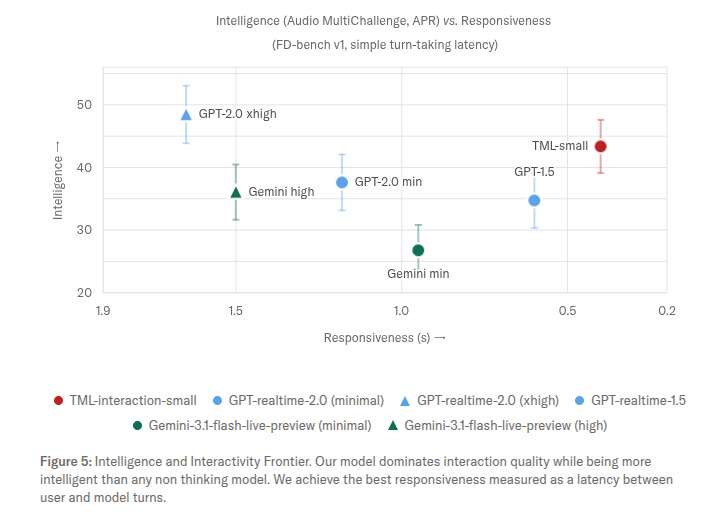
Thinking Machines claims that this dual-model architecture delivers some impressive results. On FD-bench, a benchmark designed to measure AI interaction quality, TML-Interaction-Small achieved a turn-taking latency of less than 0.4 seconds, well ahead of Google LLC’s Gemini-3.1-flash-live, which clocked in at 0.57 seconds, and GPT-realtime-2.0, which achieved a score of just 1.18 seconds.
Though speedier chatbots will be appreciated by most people, the most significant implications could be found in enterprise applications. Models that can see and react in real-time pave the way for possibilities that simply don’t exist when dealing with the latency prevalent with today’s models.
For instance, a native interaction model could be set up to monitor a video feed in a laboratory or a manufacturing facility and alert humans the moment a safety violation occurs, rather than waiting for human supervisors to stroll past and see it with their own eyes. In customer service, the lower latency can help to make calls feel more like real conversations.
What’s especially useful is that Thinking Machine’s models have an internal sense of time, which allows them to manage time-sensitive requests. A user in a lab could tell a model to “alert me if this chemical reaction takes longer than the last one,” without needing to provide any timestamps in the prompt.
Thinking Machines says TML-Interaction-Small and its partnering background model are only being made available to a select number of partners during the research preview phase, with a public release slated for later in the year.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.