







 NEWS
NEWS
NEWS
NEWS
NEWS
Koverse Inc. is attacking Hadoop’s notorious complexity with a platform that it guarantees will enable users to build a useful data lake in 30 days or less.
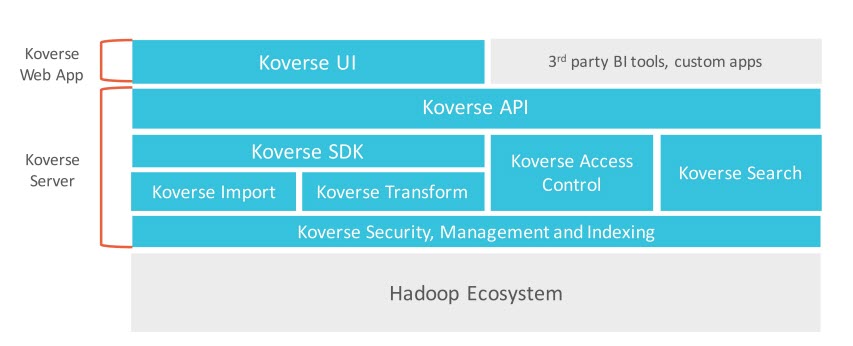
The company’s Koverse Platform Version 2.0 is built upon a patent-pending indexing engine that the company says can ingest any type of data, discover and interrogate it securely in real time with unlimited scale and support for popular analytics tools. The company believes its engine, which is built on Apache Accumulo, is the only data lake built on a key-value store. Accumulo permits the easy addition of new columns, which is useful in analytical processing.
Koverse’s founders cut their teeth building secure and scalable big data systems at the U.S. National Security Agency, including an early data lake that was used by thousands of intelligence analysts after the Sept. 11, 2001 terrorist attacks. The company, which has raised $4 milion in venture funding, was initially bootstrapped through Department of Defense contracts to bring the technology it built for the government to the private sector. “It was one of first cases where the government was ahead of the commercial market,” said CEO Jon Matsuo.
The new version of the platform makes data ingestion a self-service process with an import wizard. Koverse said this eliminates the need for any special configurations, development, data characterization or help from system administrators. “The big difference between Koverse and others is that we focus on getting everything into the data lake quickly,” said Paul Brown, co-founder and chief product officer.
A Universal Indexing Engine delivers real-time data access covering all fields in all data sets with no advanced configuration for either new or updated data sets, Koverse said. The engine automatically recognizes and indexes all data, both structured and unstructured, and provides a scalable search interface to both raw and structured data. All data is stored in raw form and can be imported without an extract/transfer/load procedure into structured data sets. Users can query data using a Google-like search and Boolean operators that can span both structured and unstructured data. Search results can be downloaded into Excel or data visualization tools Tableau Software Inc.’s Tableau. The platform also supports Python, Apache Spark, SQL and H2O.
For more involved processes, Koverse can combine multiple data sets into derivative data sets. Analytics are handled via “transforms,” which take one or more data sets and summarize or combine them to create a new searchable data set. Transforms can also be set to update automatically when any of the source data changes and can also be chained together into workflows.
The company has an interactive demo on its website that works against a live data set. Pricing was not specified.
THANK YOU





