







 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
Big-data company Qubole Inc. is beefing up Apache Spark, making it more flexible and easier to use by giving its customers the ability to run Spark applications on Amazon Web Services Inc.’s AWS Lambda service.
Apache Spark is one of the most popular big-data processing engines around, designed to execute streaming, machine learning or SQL workloads that require fast and constant access to datasets. Qubole said the ability to run Spark on Lambda, a serverless compute service that allows users to only pay for the compute power they use without needing to provision servers, makes the platform more elastic and efficient with its resource usage.
Qubole said in a blog post its Spark-on-Lambda service overcomes two major problems that previously made it a challenge to run Spark on AWS Lambda. This includes Spark’s inability to communicate directly with Lambda, something it needs to do in order to be able to run its executors. The other problem is Lambda’s limited runtime resources, which are limited to a maximum execution duration of five minutes, 1,536 MB memory and 512 MB disk space, making it extremely difficult for a memory-hungry platform like Spark to run.
To overcome these limitations, Qubole performed some technical wizardry to ensure Spark-on-Lambda service runs its executors from within an AWS Lambda invocation, thereby sidestepping the communication issues. As for Lambda’s limited runtime resources, this was dealt with by using external storage to avoid local disk size limits.
Qubole provided the following diagram to help show how Spark-on-Lambda works:
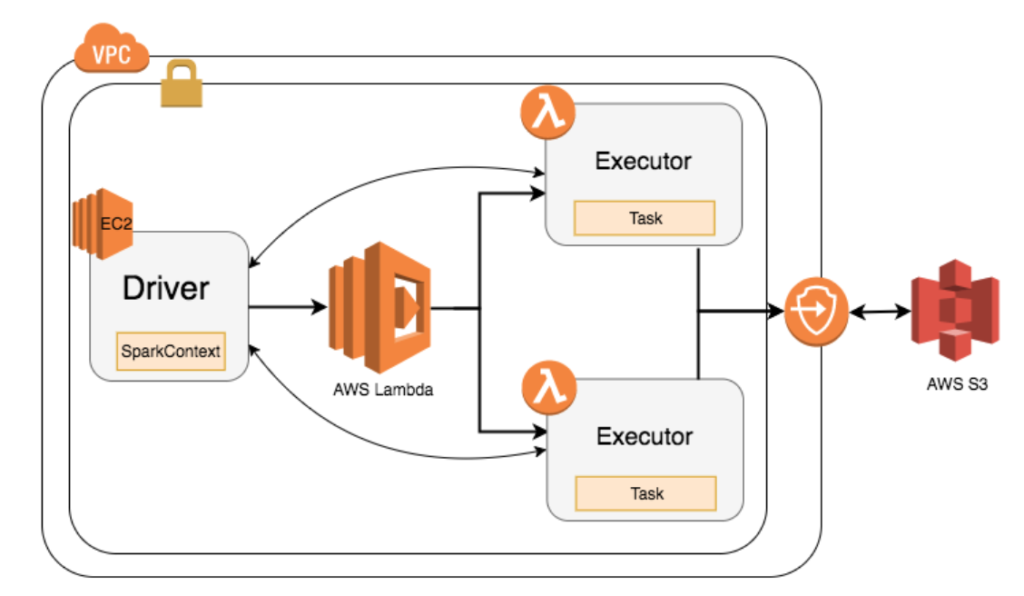
As for the benefits, Qubole said Spark-on-Lambda makes it possible to run “bursty workloads,” which are on-premises applications that are offloaded to public clouds when demand for compute capacity spikes, without needing to wait for servers to spin up first. The Spark clusters also can scale automatically with no input needed by administrators. Not least, Qubole said, pricing should be more transparent as Spark-on-Lambda invokes Lambda functions with a well-defined cost, allowing it to calculate the exact cost of each Spark workload.
“Qubole customers run some of the largest Spark clusters in the world,” said Ashish Thusoo, chief executive officer of Qubole. “We wanted to show that a complex technology like Spark can be implemented on a serverless compute infrastructure like Lambda and scale efficiently.”
Qubole said Spark-on-Lambda is currently available as a technology preview, and the company will demonstrate its capabilities during the AWS re:Invent conference in Las Vegas next week.
THANK YOU





