INFRA
INFRA
INFRA
INFRA









INFRA
Companies from all sectors are being forced through digital transformations to maintain a competitive edge and are turning to machine learning for deeper predictive and real-time analytics. Advanced machine learning models, however, require clean, consistent data streams to effectively generate value.
Outside of a handful of major players and early adopters of cloud technology, many companies are struggling to get a handle on a multitude of disparate sources of data infrastructure to take advantage of machine learning. Migrating each data store, which can number in the hundreds of thousands, into a central cloud repository poses latency challenges and can be highly cost prohibitive.
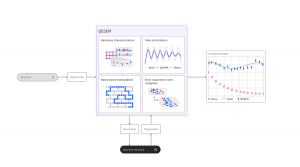
Queryplex, a data virtualization solution developed by IBM, promises to alleviate these concerns by allowing developers to treat arrays of data sources as a single repository for querying, according to Sam Lightstone (pictured), IBM fellow and master inventor.
“That gives us the ability to query data across all of these myriad sources as if they are in one place. As if they are a single consolidated data lake, and make it all look like one repository. And not only to the application appear as one repository, but actually tap into the processing power of every one of those data sources,” said Sam Lightstone (pictured), IBM fellow and master inventor.
Lightstone spoke with Dave Vellante (@dvellante) and John Walls (@JohnWalls21), co-hosts of theCUBE, SiliconANGLE Media’s mobile livestreaming studio, during the IBM Signature Moment — Machine Learning Everywhere event in New York. They discussed the impact of IBM’s data virtualization tool Queryplex on facilitating the transition to cloud. (* Disclosure below.)
Large organizations are one example of disparate enterprise data residing in hundreds of legacy repositories across vendors, formats and geographic regions. The cost for getting all of this data into the cloud is generally prohibitive, and the entire process could take a significant amount of time. The other end of the spectrum is the rapid growth sensors in “internet of things” applications, where hundreds of thousands of sources of data need to be integrated into machine learning models, according to Lightstone.
Querying each data source as part of a single virtual repository gives developers the option of leaving the data where it is while getting the benefits of a simple interface for developing machine learning models. IBM designed its API strategy with hybrid infrastructure in mind to support the various sources of data being queried, Lightstone explained.
“We’ve made it a fundamental element of our strategy in IBM to be a hybrid, what we call hybrid data management company, so that the APIs that we use on the cloud, they are compatible with the APIs that we use on-premises,” Lightstone said. “And whether that’s software or private cloud. You’ve got software, you’ve got private cloud, you’ve got public cloud. And our APIs are going to be consistent across, and applications that you code for one will run on the other.”
The differentiation between Queryplex and other forms of data virtualization is a combination of distributed processing and mesh networking among the endpoints. Rather than having each data source communicate with every other endpoint, Queryplex uses an intelligent mesh network to limit the number of connections per source and prioritize connections with the lowest latency. Queryplex also distributes the computation controller to prevent a networking bottleneck.
“We’ve designed algorithms that can truly be distributed. So you can do joins in a distributed manner, you can do aggregation in a distributed manner. … In the past, those things were hard to do in a distributed manner, getting all the participants in this universe to do some small incremental piece of the computation,” Lightstone concluded.
Watch the complete video interview below, and be sure to check out more of SiliconANGLE’s and theCUBE’s coverage of the IBM Signature Moment (IBM Machine Learning Everywhere) event.
(* Disclosure: TheCUBE is a paid media partner for the IBM Signature Moment — Machine Learning Everywhere event. Neither IBM, the event sponsor, nor other sponsors have editorial control over content on theCUBE or SiliconANGLE.)
Support our open free content by sharing and engaging with our content and community.
Where Technology Leaders Connect, Share Intelligence & Create Opportunities
SiliconANGLE Media is a recognized leader in digital media innovation serving innovative audiences and brands, bringing together cutting-edge technology, influential content, strategic insights and real-time audience engagement. As the parent company of SiliconANGLE, theCUBE Network, theCUBE Research, CUBE365, theCUBE AI and theCUBE SuperStudios — such as those established in Silicon Valley and the New York Stock Exchange (NYSE) — SiliconANGLE Media operates at the intersection of media, technology, and AI. .
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a powerful ecosystem of industry-leading digital media brands, with a reach of 15+ million elite tech professionals. The company’s new, proprietary theCUBE AI Video cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.