










 Wikibon’s CEO Dave Vellante and Principal Research Contributor Jeff Kelly co-hosted theCUBE segment dedicated to WANdisco technologies. Brett Rudenstein, Senior Product Manager of Big Data for WANdisco, was interviewed during Day Two of the Strata Conf. 2014 in Santa Clara, California, when he talked about the traction their product has had, and delivered a live demo.
Wikibon’s CEO Dave Vellante and Principal Research Contributor Jeff Kelly co-hosted theCUBE segment dedicated to WANdisco technologies. Brett Rudenstein, Senior Product Manager of Big Data for WANdisco, was interviewed during Day Two of the Strata Conf. 2014 in Santa Clara, California, when he talked about the traction their product has had, and delivered a live demo.
“Last year we announced our Non-Stop Hadoop and the people looked at our technologies wondering ‘is that really possible’?” smiled Rudenstein. “This year it’s clear that it is really possible, everyone is defining their use-cases, and they are really excited about our offering.”
“What kind of questions are they asking now?” wondered Vellante.
“The discussions revolve around being able to maximize resource utilization. Typically, people bought an insurance policy. Placing $100,000 dollars worth of equipment in a disaster-recovery data center is the insurance policy in case of a zero-availability event; if that site’s down, suddenly this equipment has value,” said Rudenstein. “What’s different now, is that everyone wants to be able to take that resource that is idle, and be able to do something with it.”
Nowadays clients are able to run secondary jobs that otherwise wouldn’t have the bandwidth to run in the primary data center, explained Brett.
.
Noticing the predominance of suits over hoodies at this year’s Strata Conference, Vellante asked Rudenstein what his audience is mainly consisting of.
“It’s mixed,” replied Rudenstein; “it’s engineers, developers, C-level execs, CIOs and CTOs, people trying to understand how it fits in their environment and how it benefits them for a more holistic global scale.”
Dave Vellante prompted a short HBase one-on-one discussion, and Brett Rudenstein obliged: “HBase is effectively a storage for big beta applications; some people call it a key value store, but the fundamental principle behind it is being able to store billions and billions of rows of data and, in the same time, have (near) real-time access to that data,” explained Rudenstein.
.
“It’s a popular database,” agreed Vellante, “but why did you pick HBase?”
“From a database perspective, the reason that it’s often picked is because of the level of scale that it’s able to achieve and also because it is fundamentally a Hadoop database. Because HBase stores its log files into HDFS, the first thing that you need is a hardened HDFS whereby you can withstand failure,” answered Rudenstein.
“The first thing we announced last year with our Non-Stop Hadoop, was an Active/Active replication of a NameNode, and geographically aware data center Hadoop. When you have that solid underpinning, you can take on an application like HBase and give it the same characteristics. Oftentimes, when people look at the kinds of NoSQL solutions that are available, they are looking at consistency and lower availability versus eventual consistency and high availability. By taking our Active/Active replication technology, putting it on to HBase, we not only allow HBase to be strongly consistent, but also continuously available,” specified Rudenstein.
“Is there a pre-requisite in order to take advantage of the full Non-Stop HBase technology?” asked Vellante.
“A best practice would be to be able to have that reliable, continuously available data storage – meaning HDFS and Non-Stop NameNode, the Non-Stop Hadoop product.”
“You could do it without a Non-Stop NameNode, but then you would make Hadoop the weak link,” commented Vellante. “So you’re advice is, go Non-Stop NameNode and then apply Active/Active to HBase.”
Brett Rudenstein agreed: “That is the right approach: you want to make sure that the foundation of your house is in a good order before you start building on top of it and that’s exactly what we’ve done.”
Jeff Kelly, Principal Research Contributor with Wikibon, wanted Rudenstein to talk more about the implications of enterprise, now that you can potentially run these cost-saving mission critical applications instead of a costly, proprietary database.
“I think it changes some of the applications that can now participate in the usage of the HBase; you can use it for applications that are mission critical (stock applications, streaming stock quotes). If HBase becomes unavailable, suddenly you no longer have that continuous availability and the business continuity. This opens up all those possibilities for continuous availability that are required for these mission critical applications,” declared Rudenstein.
.
Next up, the Senior Product Manager – Big Data with WANdisco, exemplified with a short demo.
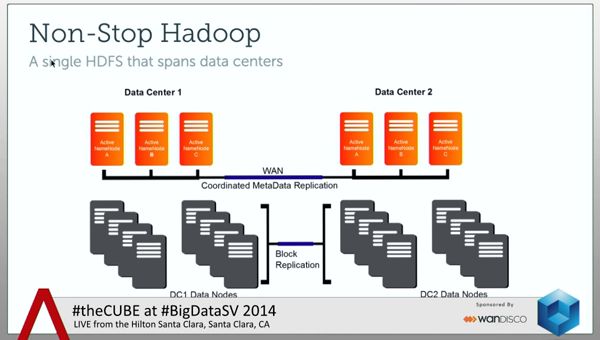
“This is a recap of where we started a year ago. We started with Non-Stop Hadoop, and that was Active/Active replication of a Hadoop NameNode, and the ability to stand Hadoop across a wide area network, or multiple geographic territories. We allowed NameNode to be continuously available – even in the event of any failure of the system and, by making HDFS available across geographic locations, you had continuously available Hadoop and wide area scope Hadoop with multi data center ingest.”
Rudenstein proceeded with a small, scale-down version demonstration, creating a MapReduce job, putting data into each HDFS and then throwing some failures at the system.

He showed theCUBE audience the quick response of the NameNodes to the event. Talking about the Foreign Blocks, he explained that by having them moving asynchronously across the system it allows for local land-speed performance while giving a complete replication of data across geographic territories.
The MapReduce application runs uninterrupted and the client can access files that are not yet available by reaching the wide area network and pulling them out in real-time. Or he can wait for the data to be replicated, and have those files locally at that point in time.
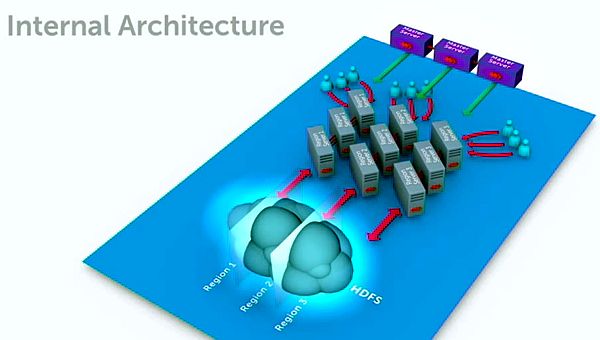
Further explaining the work process with the live demo, Rudensteing added: “Looking at the traditional architecture within HBase, we have any number of a region servers, and their job is to host these things called ‘regions’. If one region server hosting a particular region fails, that table is unavailable for that particular point in time. For that region to be able to come back online (on a different region server), several steps are required: 1) that regions server has to be identified as missing; 2) a new region server has to be elected, come online, look at the log, put it back into its mem store, and then bring it all back online.”
How long does this take?
It’s not a determined amount of time, and it depends on various things going on inside the cluster, how big the utilization is within the cluster, how big the table is and so on.
In contrast, we take WANdisco’s Active/Active technology, we can take a single region and have it hosted on multiple region servers. One region is actually available in three region servers.
The general recommendation is that each region server only allots 15 GB of memory, because they don’t want the system to slow down. With multiple Active/Active NameNodes, now that bottleneck can be eliminated.
Rudenstein noted: “For mission-critical applications you need not only consistency, but also the time-frame that suits the application service level agreements (SLAs).”
Asked to nominate several application that could benefit from applying the Non-Stop Hadoop technology, Brett Rudenstein listed the financial services, healthcare and pharmaceutical and “all the major players with mission critical applications that demand continuous access to their applications.”
Kelly wanted to know how often the HBase fails.
“When we talk about failures in a Hadoop cluster, and region servers failing, we’re talking about hardware. Hardware and disks fails in Hadoop clusters all the time. If you lose enough disks, that server becomes unavailable. This is a fairly common problem,” admitted Rudenstein, “and the larger the cluster, the more failures that you’re going to inherit.”
Kelly mentioned a certain reluctance to adopt new technologies because they don’t meet the rather strict SLAs that run in the enterprises, and asked Rudenstein to comment.
“It’s a trade-off; it’s trying to determine whether or not I can sacrifice the availability of the application for the consistency of the data within it. That’s why people sometimes get stuck relying on traditional RDBMS or things that they are very familiar with, even though they need the scale that is provided by these NoSQL solutions,” concluded Rudenstein.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





