












 Making its play for Hadoop in the enterprise, Pivotal revealed a flexible Big Data computing suite today. The joint venture between EMC , VMware and General Electric hope to ease enterprise adoption with more tools and better pricing options.
Making its play for Hadoop in the enterprise, Pivotal revealed a flexible Big Data computing suite today. The joint venture between EMC , VMware and General Electric hope to ease enterprise adoption with more tools and better pricing options.
The Pivotal Big Data Suite is a subscription-based package that bundles Pivotal Greenplum Database, Pivotal GemFire, Pivotal SQLFire, Pivotal GemFire XD, and Pivotal HAWQ, into a flexible pool of Big Data products. The suite is priced per core, and is delivered with unlimited use of supported Pivotal HD, Pivotal’s commercial distribution of Hadoop.
“With the Pivotal Big Data Suite, we are taking the lead for the industry by removing the technical barriers to data off the plates of our customers and [letting them] move to a world where the choice isn’t about Hadoop or a SQL database, in-memory or real-time processing, but to efficiency and value,” Pivotal CEO Paul Maritz said.
.
Scalability is key on all fronts, but the aggressive pricing structure for its Big Data Suite is indicative of Pivotal’s intention. Competing in a crowded market, Pivotal is going up against Amazon Web Services (AWS), Cloudera, Teradata, IBM and HP in the Big Data war. The Suite comes shortly after Pivotal launched the HD 2 version of its platform, completing the loop for its Big Data services. Stitching up its portfolio, Pivotal’s recent integration of GemFire XD and HAWQ have boosted Pivotal’s efforts in achieving enterprise readiness, according to Wikibon Senior Analyst Jeff Kelly.
“The GemFire XD announcement is a particularly important one for Pivotal, in my opinion,” wrote Kelly. “The company is betting big on its grand vision of a data layer that, among other things, allows for not just Big Data application development, but (as it calls it) Fast Data applications, including transactional applications. The vision is a single data layer that closes the analytics loop by leveraging real-time analytics for intelligent transactional workloads and large-scale Big Data analytics for historical analysis and model building that learns from and feeds the front-end transactions.”
Together with Wikibon co-founder and CTO David Floyer, Kelly developed the below model to illustrate the general concept (not Pivotal’s vision specifically) of a close-loop Big Data architecture.
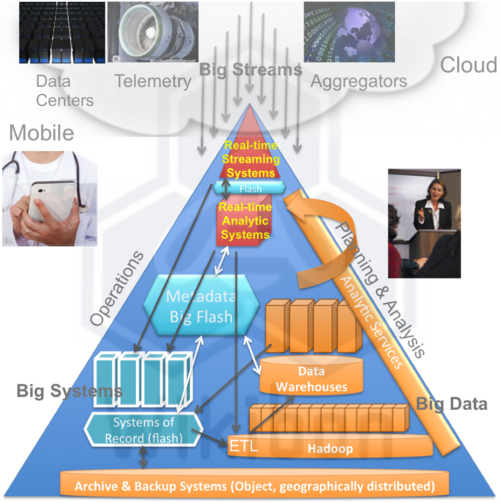
Integration of Big Streams, Big Systems & Big Data for Implementation of Enterprise-wide Integrated Applications; Source: Wikibon 2013
Pivotal has yet to disclose the exact per-core pricing of the suite, but explains that this pricing model allows CIOs and ITs to store everything without worrying about runaway software licensing and support fees. With a subscription, use of Pivotal HD, which works natively with in-memory data processing and a host of tools and analytics libraries that dramatically accelerate time-to-insight is free.
Pivotal describes the suite to be aggressively priced to blow open the doors for companies to access its Business Data Lake, where all company data is pooled together and can be used on demand to gain important insights or automate systems, when end users need to skip the IT department.
“What I can say is we have priced it to be much more competitive with the pricing expectations set by the Hadoop ecosystem than the traditional in-memory or column store customers,” Pivotal’s VP of data platform product management Josh Klahr Klahr said.
.
With today’s launch Pivotal hopes to get more approvals for its services in the enterprise, and make its way closer to the end user. To hold its own against the likes of AWS, Pivotal needs to appeal to developers. Just these past few weeks Pivotal has addressed some of its biggest challenges driving adoption, as outlined by Floyer below:
“One of Pivotal’s major challenges is melding these components into a combined enterprise Platform-as-a-Service (PaaS). The overall platform could constrain the value of each component unless the developer sees value in all the other components. Forcing adoption of enterprise platforms, particularly immature ones, top-down by corporate edict is difficult. There are a great number of alternative solutions, and the business people funding any initiative are only interested in getting their project done as quickly as possible. Even if there were a corporate edict to use Pivotal, individual programmers/small teams would take the path of least resistance to coding and testing in the shortest possible time, using Amazon (or other) cloud platforms, where the reliability, ease of integration and range of solutions are superior,” Floyer stated.
As Floyer went on to note, Pivotal also needs to maintain a dedicated focus if it hopes to differentiate itself in this crowding Big Data market. Comprised of two major “startups” under EMC’s umbrella (Greenplum and Gemfire), Floyer feels Pivotal could be pulled in too many directions. In-house integration with other members of the EMC Federation (VMware) will only contribute to Pivotal’s potential strain.
“Mobile-cloud applications will need to integrate many technologies, including in-memory databases, flash and big data Hadoop. Pushing in-house solutions is likely to diminish the Pivotal brand. Gemfire & Greenplum selling the Pivotal platform is likely to diminish their brands,” Floyer wrote.
Properly positioning Pivotal is key for EMC’s “federated” approach to restructuring its business for today’s era of the modern data center. We’ll be digging into the strategies behind EMC’s Federation next month at EMC World (see upcoming broadcast details here), particularly as IBM, Amazon and Google all promote their own visions of the modern data center.
In the meantime, check out today’s show on bringing Big Data to end users, broadcasting from Percona Live in California.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





