 NEWS
NEWS
NEWS
NEWS
NEWS
For Hadoop to become commercially viable as a Big Data operating system, it will have to drive rapid insights from dynamic information streams and address enterprise reliability standards and compliance requirements. Hortonworks and WANdisco are bringing this vision closer to reality with an integrated solution that marries active-active replication and unified analytics to facilitate the deployment of multi-purpose clusters in globally distributed environments.

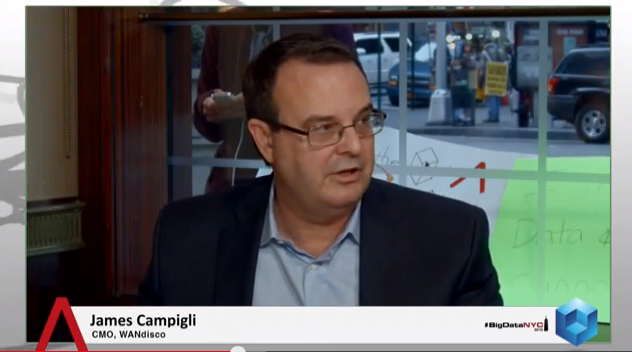
Hortonworks’ Jim Walker and WANdisco Chief Marketing Officer James Campigli dropped by theCUBE during SiliconANGLE’s recently concluded Big Data New York 2013 summit to give us a rundown of the technology behind continuously-available Hadoop.
According to Campigli, his company’s software enables use cases that were previously impossible by providing near-real time read and write access to data across multiple locations. This functionality is achieved by configuring Hadoop clusters with as many as seven NameNodes, or metadata servers, that function as fully synchronized mirrors of each other.
“At the data node level, Hadoop already does a great job of replicating the data, but the metadata – the NameNode that instructs all the client applications, the MapReduce jobs [and] where to find the data in the cluster – is effectively a single point of failure,” Campigli says.
“What we do is we use our patented NonStop technology to replicate that NameNode, so the NameNode can be clustered and clients can access multiple active NameNodes at the same time. You don’t have the single threaded situation where if that one NameNode goes down everything stops,” he explains.
Chiming in, Walker comments that Hadoop is “coming of age” in a time when organizations are exploring new processing models and embracing disruptive technologies such as YARN. WANdisco’s active-active replication solution makes it easier for multinational enterprises to join the fray and share insights on a company-wide scale.
Click the video below to watch the full discussion.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.