 NEWS
NEWS
NEWS
NEWS
NEWS
Not long ago the database technology question was simple – the answer was RDBMS, and the only question was Oracle or an alternative. Then Big Data happened. Suddenly CIOs and CTOs are being bombarded with new data types – social media, GPS, Internet-of-Things – and a tsunami of technology choices that promise to handle them but demand new, often scarce, skill sets. With Hadoop, NoSQL, high-performance streaming-media systems, graph data and a huge number of startups presenting new alternatives, it’s difficult for CIOs and CTOs to know where to start. And all the time they are hearing that Big Data is the key to the future, early adopters will gain massive competitive advantage, leaving laggards struggling in the dust.
The good news is the Wikibon Analyst George Gilbert has just published the second part (membership required) of his series on Systems of Intelligence, which organizes all the competing foundation technologies into categories and provides guidance on the appropriate uses for each. He also discusses many of the leading individual products from both established vendors such as Oracle and IBM and startups such as Storm and Data Torrent.
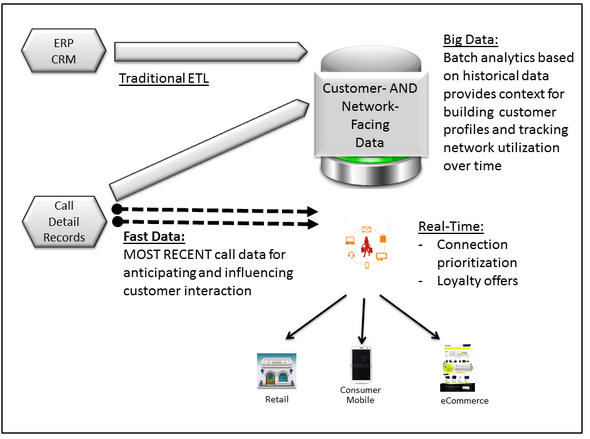
Gilbert starts with a discussion of how Systems of Intelligence differ from familiar Systems of Record. Basically he says the former are organized around data about customer interactions and related observations. This includes internal transactional data in a traditional RDBMS, social media data on what customers want or are saying about a company and its products, and Internet-of-Things (IOT) data both on what consumers are doing and on how products such as automobiles, for example, are working and when a customer should be contacted about service.
Practitioners, he says, have to manage a basic trade-off between specialized, best-of-breed tools for collecting, cleaning and integrating multiple data sources and integrated systems such as those from Pentaho Corp., which manage the entire data lifecycle from collection through discovery, visualization, BI and predictive analytics.
The analytic data pipeline needs a radical transformation, he writes. Batch migration to a data warehouse for historical reporting does not work for real-time predictive analytics. This creates another set of trade-offs, such that those between products that provide a more nuanced analysis of individual customers and those that focus more on click stream data for near real-time identification of when a customer is ready to buy.
Third, he writes, practitioners have to choose a data platform on which to build apps. This also involves a spectrum of choices from highly specialized and innovative systems through the Hadoop ecosystem to major integrated platforms such as Microsoft Azure, Amazon Web Services, IBM Bluemix and the Google Cloud Platform. He recommends that users make these decisions based partly on the skillsets they have available. Other considerations include the kinds of data that the system is to manage. He discusses the analytic data pipeline and data platform component layers in general, providing background for the more specific data platforms. He delineates four of these:
The main portion of the report looks at each of these in depth, discussing the advantages and trade-offs of each and identifying where each fits in the overall Big Data ecosystem. The message is that no one category or technology is best for all needs, and over time an enterprise may adopt more than one. For example, integrated engines are not the best choice for a system that needs to make millisecond decisions on serving an online advertisement to an individual online based on real-time clickstream data. On the other hand, a best-of-breed real time analysis system may not be the best answer for integrated CRM based on multiple sources of Big Data.
The full report looks at many of these issues in detail, providing guidance for CIOs and CTOs trying to find their way through the maze of Big Data technologies to design the best systems to meet the most important business needs of their organizations. IT executives, he writes, must be able to deliver the right infrastructure with the proper performance an SLA profile to support LOB requirements. This report is designed to equip them to make the basic decisions to move toward that goal.
The full report, “Systems of Intelligence Part 2: Foundation Platform” is available on the Wikibon Premium Web site along with the first part of this multi-part project in which Gilbert will lay out an integrated approach to designing Systems of Intelligence.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.