









 NEWS
NEWS
NEWS
NEWS
NEWS
The Apache Software Foundation welcomed two new top-level projects into its embrace last week in the shape of Big Data analytics-focused Apache Ignite and Apache Lens.
It’s fair to say that both projects have been relatively unheard of until now, but their inclusion as full-fledged members of the Apache family certainly merits a closer attention so enterprises can see what they are and where they fit into the wider ecosystem.
First up is Apache Ignite, whose development is being speadheaded by a company called GridGain. Nikita Ivanov, the company’s CTO and founder, told SiliconANGLE that Ignite can be thought of as a “high-performance, integrated and distributed in-memory data fabric for computing and transacting on large-scale data sets in real-time, orders of magnitude faster than possible with traditional disk-based or flash technologies”. He explained that Ignite is built to power both existing and new applications in a distributed, massively parallel architecture on affordable, industry-standard hardware.
At first glance, observers might be forgiven for thinking Ignite sounds quite similar to the much better known Apache Spark. Indeed, both Ignite and Spark use in-memory as the main storage paradigm. But Ignite can’t really be considered a Spark competitor in the same way that something like Apache Flink could be, because that’s where the similarities end, Ivanov insisted.
According to Ivanov, whereas Spark is designed for interactive analytics and machine learning applications (i.e. geared toward a use case where a data scientist is interactively working with the system through some sort of GUI), Ignite is designed to deliver programmatic real-time analytics, machine-to-machine communication and high-performance transactional processing.
“Apache Ignite fills a gap in the ecosystem by providing a solution for high-performance transactional processing and real-time machine analytics,” Ivanov said. “That’s something that neither Hadoop nor Spark were designed to do.”
In theory then, Ignite should actually be quite complementary to Spark, depending on the scenario. One of Spark’s biggest weaknesses is that it lacks an integrated data storage layer. Instead, it uses external storage layers such as HDFS, HBase or Cassandra.
Ignite acts much like an in-memory database that allows Spark to process in-memory alone. The idea is that Ignite helps Spark to figure what should stay in-memory and what can be stored persistently, giving users unprecedented performance and scalability benefits.
Ignite is typically used in transaction processing systems like trading, fraud protection, real-time modeling and real-time analytics, Ivanov said. It works equally well with horizontal scaling on commodity hardware and with vertical scaling on high-end workstations and servers.
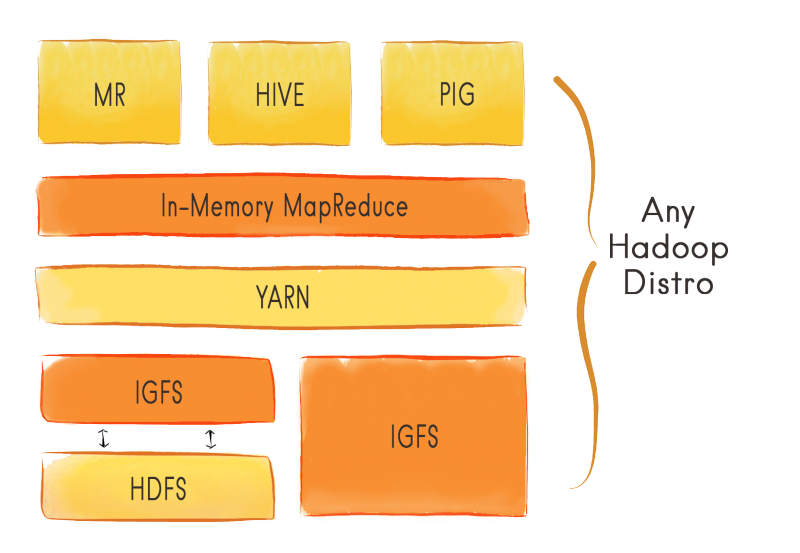
Graphic showing where the Ignite File System (IGFS) fits into the Hadoop ecosystem
Ignite’s full potential probably won’t be realized for some time. Although Ignite has gained lots of traction with “hundreds of production installations”, the project has actually been designed with future memory types like NVDIMMs, storage class memory or 3D xPoint in mind, Ivanov said.
“There’s tremendous innovation happening in memory space and our vision is to have Apache Ignite be at the forefront of supporting these new and revolutionary types of memory,” Ivanov said.
Apache Lens is intended to fill a different gap in the Big Data ecosystem. The Apache Software Foundation describes Lens as “a unified analytics platform. It provides an optimal execution environment for analytical queries in the unified view. Apache Lens aims to cut out the Data Analytics silos by providing a single view of data across multiple tiered data stores.”
To understand what Lens is all about, we turned to Amareshwari Sriramadasu, a VP of Apache Lens who works as a data platform architect at InMobi, Inc., a mobile advertising network that’s one of the major backers and users of the project.
Sriramadasu told us that one of the problems large enterprises and Web companies face when tapping into Big Data is juggling many different data sources, including conventional SQL databases, file system based sources (such as HDFS) and in-memory databases. All of these data sources have their own sweet spots when it comes to the query classes they’re suited for, which is why it’s difficult to consolidate everything into a single database.
This is where Lens comes in; it provides a single end-point for a user to query data irrespective of where and how data is stored, effectively allowing multiple data sources to be seen as a single data warehouse. Lens is able to provide a single view of these data sources and to choose the best source for every user query. Lens also has the ability to understand data hierarchy and relationships using cube definitions.
“This enables the Lens system to find the cheapest way to access information for a user query,” Sriramadasu told us. “For example, if sales data is available at a city level and also at a country level, the Lens system can understand this hierarchical relationship and access data at a country level when the user is interested in sales at a broader geographic region as opposed to finer city level data which might have higher cardinality.”
Sriramadasu explained that Lens solves a couple of major problems that other Big Data technologies don’t:
Lens, therefore, is positioned as complementary to query execution engines like Hive and SparkSQL, both of which make data on HDFS and HBase accessible through SQL-like constructs. According to Sriramadasu, Lens provides a logical data warehouse view with OLAP constructs over Big Data SQL engines, traditional RDBMS and in-memory databases. Lens sees these data sources as a continuum as opposed to being silos.
The following figure shows us where Lens fits into the Hadoop ecosystem, providing an OLAP extraction layer atop data processing and query frameworks/languages such as Hive, SparkSQL and Pig. Lens can be then be used with Zeppelin and other BI engines for analytics and visualization.
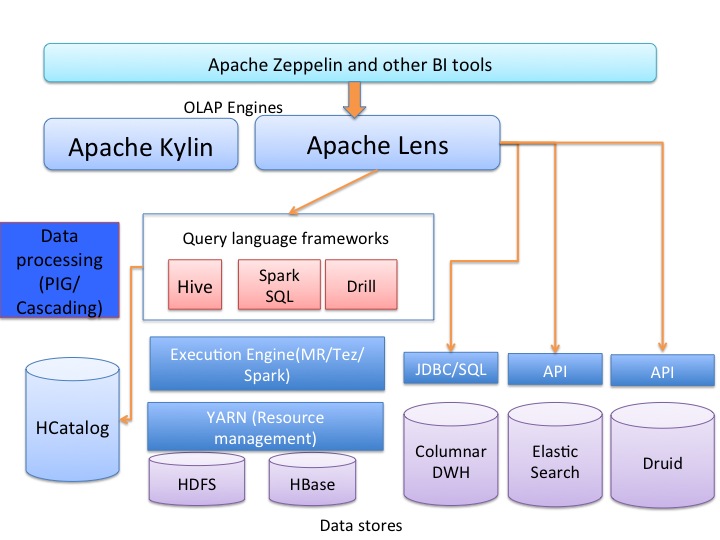
For a detailed explanation on how Lens can be put into practice, check out this blog post by InMobi’s Jothi Padmanabhan.
Lens is still an immature technology, but it already has a number of big names behind it, with InMobi, Flipkart Internet Private Limited, Lazada Software AG, Hortonworks Inc. Snapdeal.com and Talend, Inc. all contributing to its development.
As for what the future holds, InMobi said it believes Lens will eventually become the de facto data access and data discovery mechanism for any organization that run big data stack alongside conventional database stack.
“Over a three-year horizon, we expect Lens to be widely deployed and used in production,” Sriramadasu said. “Just as Lens has enabled OLAP abstractions over relational tables across datastores, we hope to build capabilities in it that will allow other representations such as graph traversals.”
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





