NEWS
NEWS
NEWS
NEWS
NEWS
Google will be feeling pretty pleased with itself after its Cloud Dataflow service outperformed the immensely popular Apache Spark data processing engine in a recent benchmark study carried out by Mammoth Data Inc.
There’s a caveat of course, because Google hired Mammoth Data to carry out the Benchmarking Google Cloud Dataflow study on its data processing service and programming model. Dataflow is a paid service, but the platform’s API was recently accepted as an incubator project with the Apache Software Foundation under the name Apache Beam, following a submission earlier this year.
As if to emphasize its neutrality, Mammoth Data pointed out that it actually uses Apache Spark for its own consultancy business. As such, it carried out a fully “object study”, the consultancy said. “Given our real-world experience with Hadoop and Spark, Google asked us to ‘kick the tires’ and share our insight and findings — both good and bad,” Mammoth Data said in a statement.
The results were extremely good for Google however, with Dataflow more than doubling the performance of Spark in several key metrics. For example, Dataflow beat out Spark by five times on smaller clusters, and by two times with larger clusters, Mammoth Data said.
“Spark did show near linear clock time performance gains as we deployed larger clusters, whereas the Dataflow curve is much more gradual,” it continued. “We also noticed that it would take approximately 8x Spark resources to achieve the slowest Dataflow job runtime (128 cores). This is a key point when considering both cost implications and resource capacity planning.”
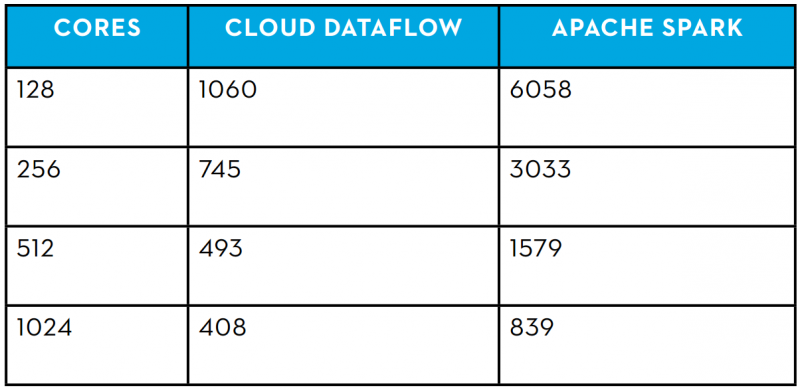
Clock Time Performance comparison (Time in Seconds) via Mammoth Data
Mammoth Data also offered some observations on the autoscaling functionality, ease of use and programming models (useful for developers) of both platforms, saying that Dataflow once again came out on top, especially when using historical data.
“One noticeable advantage of Cloud Dataflow over Spark in this use-case is that Spark’s built-in windowing functions do not work with ‘synthetic’ timestamps; you can only window over data based on the time Spark actually receives the data, not a timestamp stored with the data,” the report said. “This makes it very difficult to use Spark for working with historical data in batch mode.”
In contrast, Mammoth Data said that Dataflow’s native windowing functions were straightforward to use, and made it much easier to implement the pattern. It added that using Spark also necessitated “massaging” some of the cache and storing options so as to avoid running out of memory during benchmark runs. Dataflow, on the other hand, could automatically manage resource optimization, even with smaller node clusters.
Mammoth Data said it didn’t use the advanced windowing and trigger features of Dataflow, but nevertheless its experience was similar to Google’s own programming model comparison, which it published in February of this year.
That comparison states that: “Dataflow provides the flexibility and power necessary for the next generation of real-time data-processing systems, with a clear, practical and robust approach to out-of-order processing. It goes without saying that we’re very excited by the possibility of bringing all of this to an even larger audience, thanks to the creation of the Apache Beam incubator project (which, incidentally, includes work from our friends at Cloudera and PayPal to begin bringing the Dataflow model to the Spark runtime).”
Further addressing the programming aspects, Dataflow can be easily integrated with Google services like Cloud Storage and Big Query, Mammoth Data said in its study. As such, it provides a “batteries included” experience for those who’re already using Google’s Cloud.
Still, Google and Dataflow didn’t have it all its own way. According to the study, “There are not many custom source and sinks as compared to the greater Hadoop and Spark ecosystem,” Mammoth Data said, though it added that this may change as development progresses on Apache Beam.
Mammoth Data performed three tests in its study: comparing clock time performance with a varying amount of cores; a variance test with smaller instance sizes; and Dataflow with autoscaling.
It said that Dataflow was found to be lacking when it comes to ease-of-use, particularly when running in local execution mode, which contrasts with the performance of Spark’s read-eval-print loop (REPL), which offers interactive analysis via Spark Shell.
“Dataflow’s local execution is great for behavior testing, but it’s a poor substitute for the flexibility of using Spark’s REPL for interacting with data before creating a standalone application,” Mammoth Data’s report said. It added that it was a big challenge to even get the benchmark to run on Dataflow, as it was unfamiliar with Dataflow’s job-centric model and API.
“While there have been some teething troubles as Google Cloud Dataflow matures, it is already a serious competitor to Apache Spark as well as other cloud Hadoop offerings,” the report concluded. “Ultimately, Cloud Dataflow provides a flexible and developer-friendly set of APIs as well as a vastly simpler and efficient story for deployment and execution of pipelines. At Mammoth Data, we’re excited to have Google opening up its Big Data expertise for all to take advantage.”
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.