









 AI
AI
AI
AI
AI
Google LLC’s artificial intelligence research unit has made some big advances in its efforts to build a system that can accurately distinguish among different human voices.
The system employs something called “speaker diarization,” defined as the process of partitioning out a speech sample into distinctive homogeneous segments according to which speaker said what.
This process comes fairly easily to humans, but for computers it’s an entirely different story that requires advanced machine learning algorithms to train them in order to pick out individual voices. The problem with speaker diarization is that algorithms must have the ability to associate new individuals that weren’t involved in their actual training, with distinct speech segments.
That isn’t easy, but Google AI research scientist Chong Wang said in a blog post that his team has managed to build a new AI system that employs “supervised speaker labels in a more effective manner.”
Current methods to achieve speaker diarization are not so effective because the training methods are “unsupervised,” using unlabeled data. However, Google’s new method, detailed in a new white paper, ensures that all components in the speaker diarization system are trained in supervised ways. This means they can benefit from increasing the amount of labeled data that comes available as the system listens to various speakers.
The approach involves modeling each speakers’ “embeddings,” or a mathematical representation of the words and phrases they speak. This is done using a recurrent neural network, which is a special kind of machine learning model that can use its internal state to process sequences of inputs. Each speaker is given its own RNN instance, which continuously updates the state of the RNN with new embeddings, enabling the system to learn and understand what’s being said by each individual.
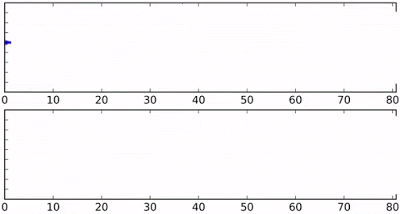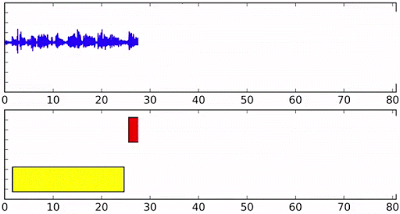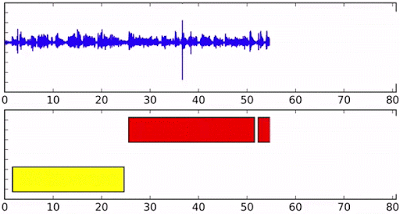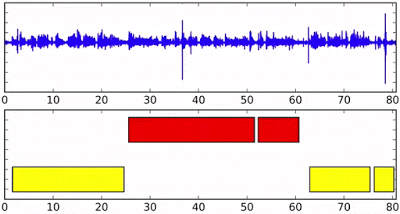
Online speaker diarization on streaming audio input. Different colors in the bottom axis indicate different speakers.
Wang claimed that the system is accurate enough to achieve an online diarization error rate of just 7.6 percent on the NIST SRE 2000 CALLHOME benchmark, which is good enough for use in real-time applications.
“Since all components of this system can be learned in a supervised manner, it is preferred over unsupervised systems in scenarios where training data with high quality time-stamped speaker labels are available,” the researchers wrote in the paper. “Our system is fully supervised and is able to learn from examples where time-stamped speaker labels are annotated.”
The researchers said speaker diarization can be applied to many useful scenarios, including where multiple speakers talk to digital assistants such as Amazon Alexa or Google Assistant, understanding medical conversations and captioning videos.
Analyst Holger Mueller of Constellation Research Inc. said it appears that Google is pushing the envelope on user interaction with smart devices as voice is a natural input method, given that humans can speak faster than they can type.
“But speech recognition is hard in noisy environments, particularly when multiple people are speaking,” Mueller said. “So any progress in this arena is going to propagate the adoption of voice further.”
Wang’s team is now planning to refine the model so it can also integrate contextual information, which should help to further reduce error rates. In the meantime, they’ve also decided to open-source the new algorithm and make it available on GitHub, so others can contribute.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





