AI
AI
AI
AI
AI
Facebook Inc. is using its @Scale conference today to provide an update on its progress in artificial intelligence research.
The social media company is open-sourcing a new “AI reasoning” platform and providing some updates on its research into machine translation.
It’s part of a broad push to scale up AI workloads, a difficult task given the massive amounts of data needed to train AI models, Srinivas Narayanan (pictured), the lead for Facebook’s Applied AI Research, said this morning at the conference in San Jose, California.
“Facebook wouldn’t be where it is today without AI,” Narayanan said. “It’s deeply integrated into everything we do.” But with more than 10,000 AI models making trillions of decisions a day, finding ways to do all this more efficiently is critical. “With this massive growth comes massive scaling challenges,” he said.
AI reasoning refers to computer systems that are able to extract critical information from large sets of structured and unstructured data and come to logical conclusions based on that information. Facebook said reasoning models an “incredibly important” aspect of AI, used in many recommendation engines, surfacing new products that online shoppers might be interested in, or recommended TV shows that a user might want to watch next, for example.
AI reasoning models are trained using reinforcement learning, which is a programming method that trains algorithms using a system of reward and punishment. A reinforcement learning algorithm, or agent, learns by interacting with its environment. The agent receives rewards when it performs correctly and gets penalties when it is incorrect. Through this, the agent is able to “learn” without human intervention by maximizing its rewards and minimizing its penalties.
The only problem with reinforcement learning is that it’s such a difficult and time-consuming process to setup that very few organizations have the resources necessary to train their AI models in this way. And so Facebook has decided to open-source its ReAgent platform, which makes it easier to build AI reasoning models, to overcome these challenges.
ReAgent, now available to download on GitHub, comes with pre-built models that already can make decisions based on the data they’re fed and also can provide feedback on those decisions. In addition, there’s an “offline evaluator module” that can estimate how new models will perform before they’re deployed in production, plus a serving platform for deploying models at scale.
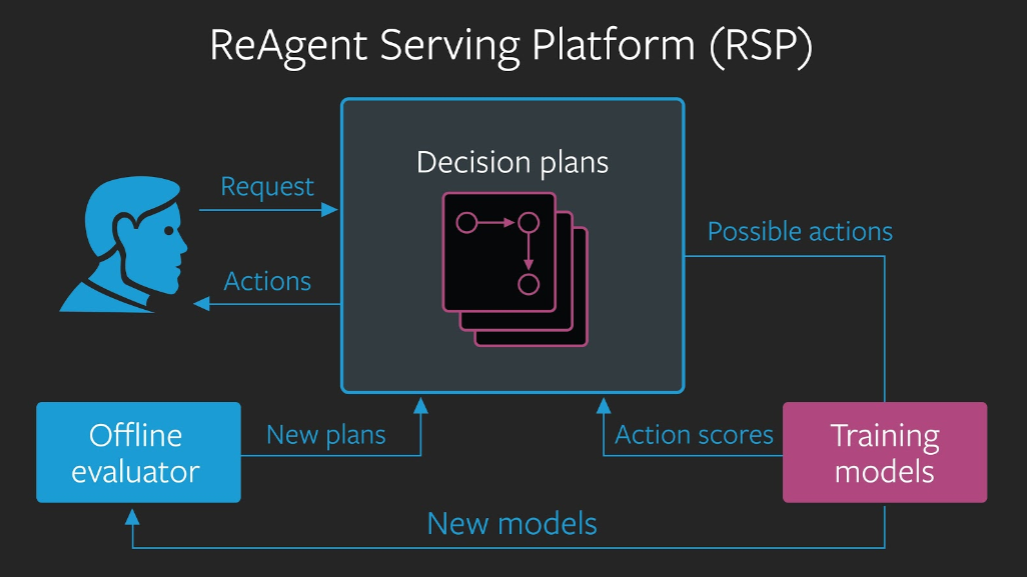
“It’s the most comprehensive and modular open source platform for creating AI-based reasoning systems, and it’s the first to include policy evaluation that incorporates offline feedback to improve models,” Facebook’s AI research team wrote in a blog post. “By making it easier to build models that make decisions in real time and at scale, ReAgent democratizes both the creation and evaluation of policies in research projects as well as production applications.”
Facebook already uses ReAgent internally to power many of the personalization decisions its social media platform makes, such as deciding which notifications to show users, it said. Facebook said it’s making ReAgent more accessible to organizations with new documentation that explains how it can be deployed to public cloud computing services such as Microsoft Azure.
“This expanded compatibility will further democratize the use of RL in production and expand the AI community’s understanding of how models can improve their ability to make and assess decisions, including in real time,” the Facebook researchers said.
Facebook has also made some advancements on the machine translation front. Its researchers say they’ve come up with a new technique for teaching systems how to translate spoken words into more obscure languages for which there aren’t thousands of examples that can be used as training data.
Machine translation is an application of natural language processing that trains models on large collections of sentences in both the source language and corresponding translations in the target language. Such models are extremely accurate when it comes to widely spoken languages for which there is lots of data available, such as English-to-Spanish translations. But they don’t do quite so well when it comes to “low-resource languages” such as Lao, Kazakh, Haitian, Lao, Oromo and Burmese, for example.
Facebook’s new technique to overcome this, which involves combining “iterative back translation” and “self-training” with noisy channel decoding, has enabled Facebook’s researchers to create a new English-to-Burmese machine translation system despite only having limited data on the target language.
Back translation is a training method that assumes there must be a significant volume of monolingual data in the target language and that the subject matter of sentences in both source (e.g., English) and target languages (e.g., Burmese) should be comparable. But the method is not effective in the case of low-resource languages, since there’s not enough monolingual data available. Facebook’s new technique provides a workaround for that problem.
“First, using the limited parallel data available, we train a reverse MT system that translates from the target to the source language,” the researchers wrote. “We then use this system to translate monolingual data on the target side, which produces a synthetic data set composed of back-translations from the reverse MT system and the corresponding target sentences.”
The next step involves running a self-training algorithm based on this newly created synthetic data set to translate the monolingual data from the source language into the target language. That produces a second synthetic data set made up of sentences from the original monolingual data and their corresponding machine translations.
“After using back-translation and self-training to produce synthetic data sets with back-translated and forward-translated sentences, respectively, we combine all these data sets and retrain both a (potentially bigger) forward model and a reverse model,” Facebook’s researchers wrote. “As the translation quality of these models improves through retraining, we reuse them to retranslate the source and target monolingual data sets.”
Constellation Research Inc. analyst Holger Mueller told SiliconANGLE the new research demonstrates that Facebook is at the forefront of machine translation research.
“Given its global social network market share, Facebook believes it needs to push AI-based translation further than any vendor,” Mueller said. “And Facebook is doing exactly that, now supporting off-the-mainstream languages for translation.”
With reporting from Robert Hof
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.