AI
AI
AI
AI
AI
Google LLC today shared how it has worked with the nonprofit organization StoryCorps Inc. to digitize an enormous archive of human story audio recordings using some of its most advanced artificial intelligence technologies.
StoryCorps’ mission is to record, preserve and share the stories of Americans from all backgrounds and beliefs. The project was founded back in 2003, and since then it has recorded one-on-one interviews with more than 600,000 people. Those recordings are stored at the American Folklife Center in the U.S. Library of Congress, where they are being preserved for future generations.
The StoryCorps archives are believed to be the largest collection of human voices on the planet, but up until recently those stories have been inaccessible to most people. To change that, StoryCorps approached Google to ask if it could help make its rich archive of history universally accessible to anyone who’s interested in listening to them.
In a blog post, Andrew Moore, head of Google Cloud AI & Industry Solutions, said StoryCorp’s mission struck a chord with Google:
“StoryCorps’ mission is impressive. Not only is it preserving humanity’s stories, its aim is to “build connections between people and create a more just and compassionate world” by sharing those stories as widely as possible. This is where our path with StoryCorps crosses on a deeper level.
Our mission for AI technology is one where everyone is accounted for, extending well beyond the training data in computer science departments. This deeper understanding could allow organizations in every sector to unlock new possibilities of what they have to offer while being inclusive, equitable and socially beneficial.”
StoryCorps wanted to know if it were possible to somehow use its archive to build an open database of searchable audio recordings, and Google quickly realized that its AI tools could do this.
Moore explained that in order to make an audio recording searchable, it’s necessary to first transcribe each one, and then tag the most important keywords, or “moments” in each one, using terms that people would usually search for.
So Google set about doing that, first by using its Speech-to-Text API to transcribe the audio files one by one. Once that was done, it employed its Natural Language API to identify “keywords and their salience” from those transcriptions.
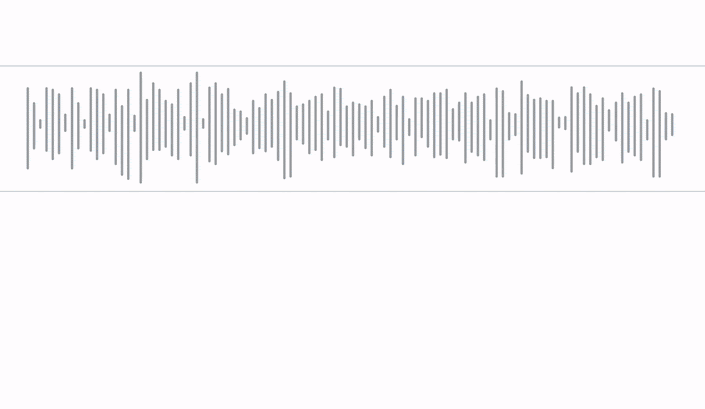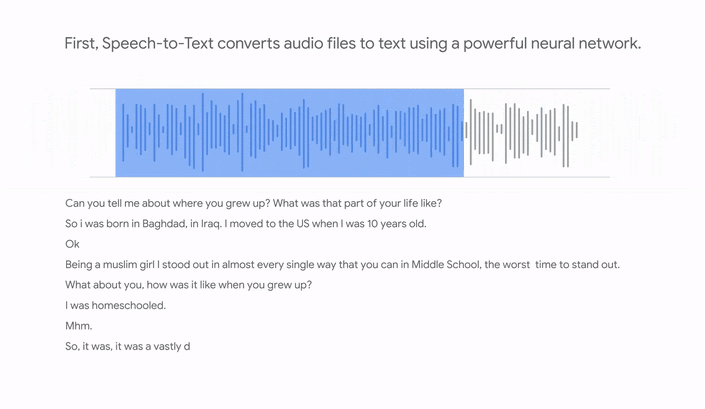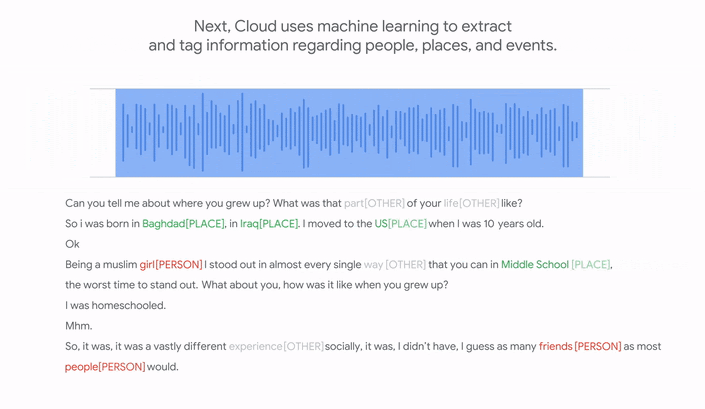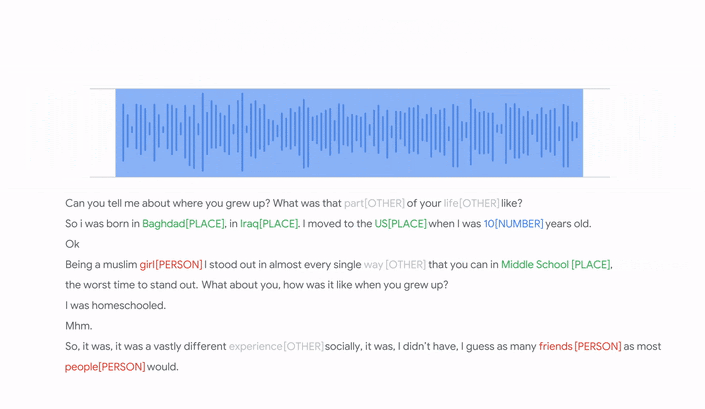
The transcripts and their keywords were then loaded into an Elasticsearch index, resulting a fully searchable archive that enables anyone to “listen to first-hand perspectives from humanity’s most important moments,” Moore said.
StoryCorps’ entire archives can now be accessed from its online platform and its mobile application.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.