









 CLOUD
CLOUD
CLOUD
CLOUD
CLOUD
Amazon Web Services Inc. today announced the general availability of Aqua, a technology that uses custom chips designed by the cloud giant to help organizations run analytics queries faster on Amazon Redshift.
AWS says that Aqua will enable customers to perform some data operations up to 10 times faster than competing platforms.
Amazon Redshift is a managed data warehouse that companies use to support business analytics projects. The information customers work with as part of their analytics projects is stored on AWS’ S3 storage infrastructure. When customers wish to process the information, they can send it over to a cluster of compute instances tied to their Redshift environment and use the instances’ virtual central processing units to run queries.
That arrangement makes it possible to provision compute and storage resources separately, which helps optimize costs. But there’s a tradeoff. Moving information between storage infrastructure and compute instances can take a considerable amount of time when large datasets are involved, which delays queries. With Aqua, AWS is promising to address the bottleneck.
Aqua speeds up processing by bringing “compute to the storage layer,” explained Rahul Pathak, AWS’ vice president of analytics. The cloud provider is thereby reducing the need for companies to move information they wish to analyze over the network between their compute instances and storage infrastructure, which avoids the associated delays. The result, AWS says, is up to 10 times better performance for certain types of analytics queries than competing cloud-based data warehouses.
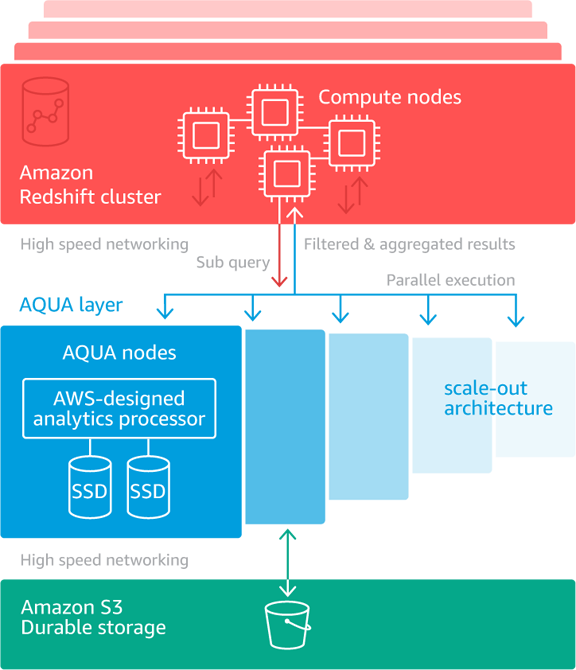
Under the hood, Aqua is powered by specialized hardware modules in the cloud giant’s data centers that use “AWS-designed analytics processors” to perform data processing tasks. The technology is available as part of Redshift RA3 instances at no additional charge.
“The benefit comes about in several different ways,” explained AWS Chief Evangelist Jeff Barr. “Each node performs the reduction and aggregation operations in parallel with the others. In addition to getting the n-fold speedup due to parallelism, the amount of data that must be sent to and processed on the compute nodes is generally far smaller (often just 5% of the original).”
One of the customers that has adopted Aqua in its Redshift deployment is AWS parent Amazon.com Inc.’s advertising business. According to AWS, the unit can run 50% more queries in its Redshift environment for the same cost as before, while some data operations now complete in one-10th the time.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





