









 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
Graph database maker Neo4j Inc. today introduced a version of its Aura managed service aimed at data scientists.
The new offering complements an existing managed version of its core graph database the company rolled out early last year.
Coincident with the announcement, Neo4j also announced version 2.0 of its Graph Data Science software, containing 65 new graph algorithms, better data import capabilities and support for MLOps, which is a machine learning engineering discipline focused on speed and continuous development.
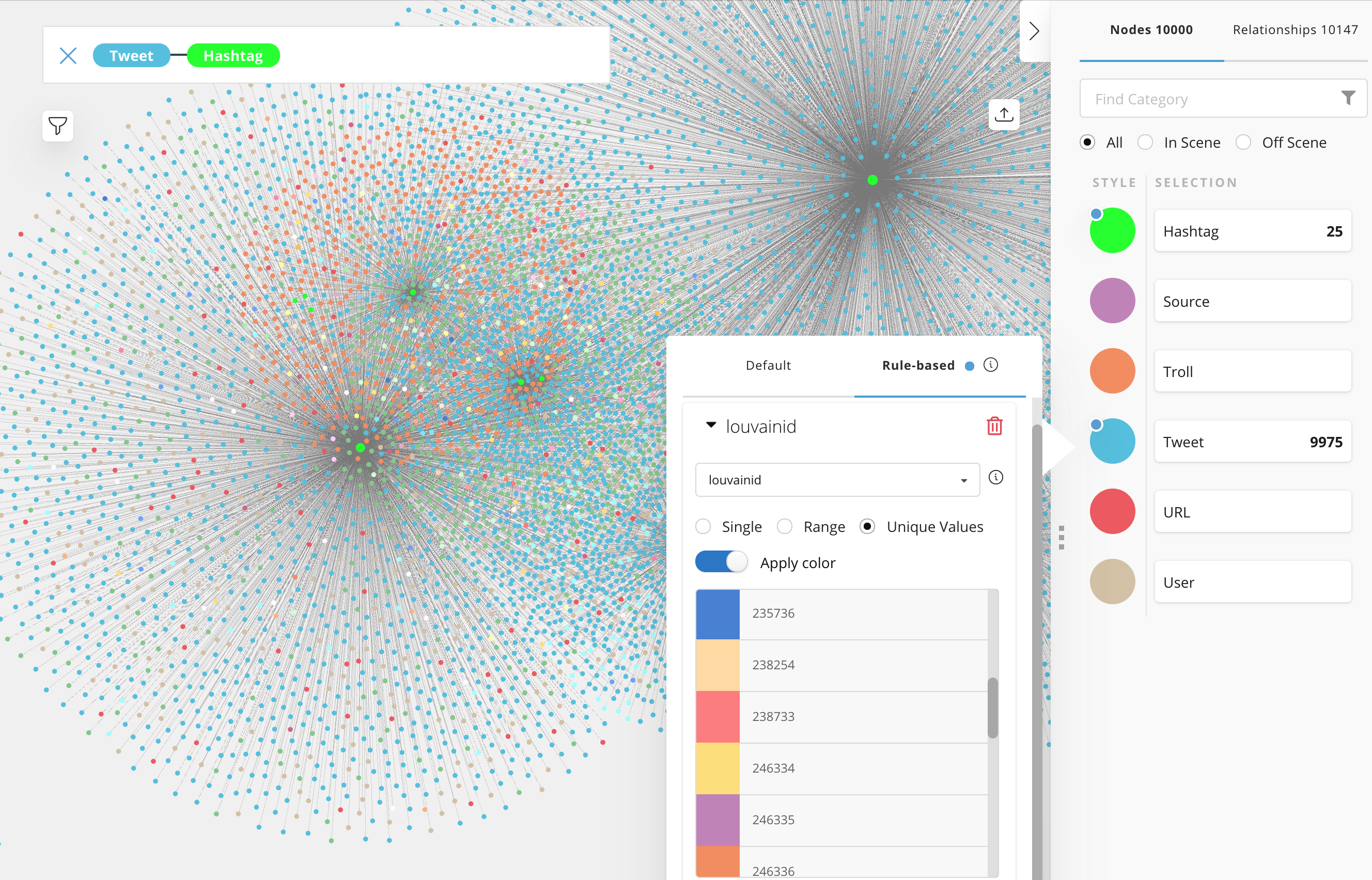
Graph databases excel at representing complex relationships in ways that can be quickly and easily navigated to discover correlations, such as how many of your Facebook friends are also connected to at least five of your other Facebook friends. One of the best-known applications of graph analytics is search engines, which rank website relevance based on both the number and quality of inbound links.
Data science is “a growing segment of our enterprise customers that made up about 30% of new customers last quarter,” said Alicia Frame, senior director of graph data science at Neo4j. She said about 20% of all customers are using some version of the company’s product for data science.
AuraDS has all the usual managed service features, including automated patching and backup and pay-as-you-go pricing. The new offering also allows users to take a snapshot of instance models and in-memory graphs with one click and pause instances without saving them.
The graph algorithms included in this release address such data science-specific functions as finding the shortest path across a graph, identifying which nodes are connected to other nodes and those that are most similar to each other. A drag-and-drop import feature supports comma-separated value format and has an Apache Spark connector that enables import from data warehouses.
Managing pipelines is made easier through the addition of a pipeline catalog, a new unified syntax for model configuration, training and application, and support for random forest models. There’s also native support for popular data science algorithms like Breadth-First Search, Depth First Search, K-Nearest Neighbors and Delta Stepping.
This version also features native support for Python, a popular data science development language. This eliminates the need to write configuration scripts and application program interface code that was previously necessary. “Now they can use Python in a Jupyter notebook and not have to worry about syntax and integration with their workflows,” Frame said.
Neo4j is positioning the product as a complement to, rather than a replacement for, conventional data science toolsets. “It’s a ‘better together’ story,” Frame said. “Graph is really good in terms of feature engineering but it’s important to fit into the ecosystems that data scientists live in.”
That’s why the company has focused on easy export into existing data science pipelines. “Graph is a powerful tool but we’re not saying throw out your establish machine learning,” Frame said.
Pricing is expected to be similar to the existing database offering.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.






{kind=link}