









 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
It’s always tempting to say that things were simple in the old days. But speak with any surviving COBOL or Fortran programmer, especially those who had to deal with punch cards or rotating drums, and the old days look anything but simple. Still, when it came to engineering roles, there was a fairly rudimentary breakdown: The systems person handled the hardware and the software engineer presided over code.
The world obviously has become more complicated since then. Emergence of distributed systems gave rise to databases that maintained the data outside of the program, now called an application. Computing languages proliferated like rabbits as simplified languages, such as Visual Basic, gave hope of a living wage for countless liberal arts majors.
That amplified the role of software engineering, as there needed to be adults in the room to ensure that the code has been properly developed and maintained. New iterative, then agile software development processes supplanted traditional waterfall approaches. And as system architectures grew more distributed and complex, and software releases grew more frequent with agile and scrums, software engineering had to factor in operations – and so begat DevOps. Software engineering was always about complexity, but with distributed systems and agile processes, the nature of the complexity changed.
But through all this, data was regarded as an application problem. Yes, you needed database administrators to model and physically lay out the data, and then keep the database humming. But the interactions with data tended to fall into a few buckets: Transaction databases were primarily occupied by single row operations, while data warehouses were largely batch operation affairs.
Our own journey through the field mirrored the perception. During the client/server era and the run-up to Y2K, relational databases became the default. When the internet broke relational databases with their transaction volumes, the action shifted to the application server in the middle tier, which handled state management. And so, we spent the next decade tracking middleware.
But then the data got so humongous that it swung the pendulum the other way; the air was sucked out of the middle tier as processing moved back to the data. Big data. Polyglot data. And so, operations against data became anything but a closed-book affair. To design anything from ingest to complex exploratory querying, developers writing MapReduce programs had to know not only Java, but the behavior of data, and more specifically, what was the best sequence of processing operations, not only to get the job done, but get reliable results. And this was before the cloud came in, which exploded scale even further and forced yet a new pendulum swing for separating compute from storage.
Sorry to say, but this was no longer a software engineering problem. An engineer was needed who knew the behavior and shape of the data. Enter, from stage left, the data engineer.
According to Indeed.com, data engineering, along with full stack developer and cloud engineer, have supplanted data scientist as the most sought-after tech job. In all this maelstrom are a couple of self-described “recovering data scientists,” Joe Reis and Matthew Housley, who leaped into the void of defining just what exactly a data engineer is.
We recently had the opportunity to have a deep-dive discussion with them, better known as the authors of the bestseller “Fundamentals of Data Engineering.” Both came to data engineering after data science stints, where they learned the hard way that they had to spend more time wrestling with data in order to develop, train and run models. Their experience very much jibed with research we conducted during our Ovum days nearly five years ago in conjunction with Dataiku. Namely, that if you’re a data scientist, consider yourself lucky if you only have to spend half your time dealing with data.
As noted above, data engineering emerged when the cloud and big data made data interaction far more complex, scaled and dynamic compared with the good old days of running against a walled-garden database in the data center. It emerged alongside other disciplines such as site reliability engineering that grew necessary because the cloud introduced more moving parts.
As initially envisioned, data engineering was an attempt to apply the disciplines of software engineering to the data lifecycle. Reis and Housley get more specific: It’s about building in testing, continuous improvement and version control to the data lifecycle and, stretching the envelope a bit, observability. With the cloud and big data, touching the data could no longer be treated as a static, single-row insert or batch-process black box. Big data introduced more varied data types and sources, and the cloud introduced far more moving parts.
Specifically, the cloud broke down all the traditional barriers that constrained data interactions in the data center. All elements of infrastructure, from compute to storage and connectivity, grew far cheaper, taking advantage of commodity technology. It paved the way to decoupling all levels of the architecture, which meant more parameters to deal with, and the need to optimize.
Optimization is not a new concept in the database world, but in the cloud, there’s much more surface area to optimize. Specifically, the cloud changed from managing capacity to managing resource. The rationale for optimization, such as tiering data or determining the right sequence of operations for a complex query, hasn’t changed. But there is the need to apply such thinking to more “parts,” such as where to transform data.
Should it still be done traditionally, outside the database (ETL), or in-database (ELT) because the storage is much cheaper? For instance, though ELT has become the more popular choice, if streaming is involved, traditional ETL (but performed on a stream-of-change feed) may still be the more practical answer.
According to Reis and Housley, the profession or discipline of data engineering is still poorly defined, which is why they wrote their book. They have attempted to dive into the void by defining requirements for skills and knowledge. Clearly, there’s a lot to borrow from software engineering, such as best practices for continuous testing and integration in the context of operations. And from that comes the discipline of DataOps.
Reis and Housley emphasize that it requires more than trusting your fate to tools and being a tools jockey: Look under the hood to understand how the tool does its job, or what’s lurking beneath the surface of an API. Understand what the tool is doing as if you had to code or configure the process yourself.
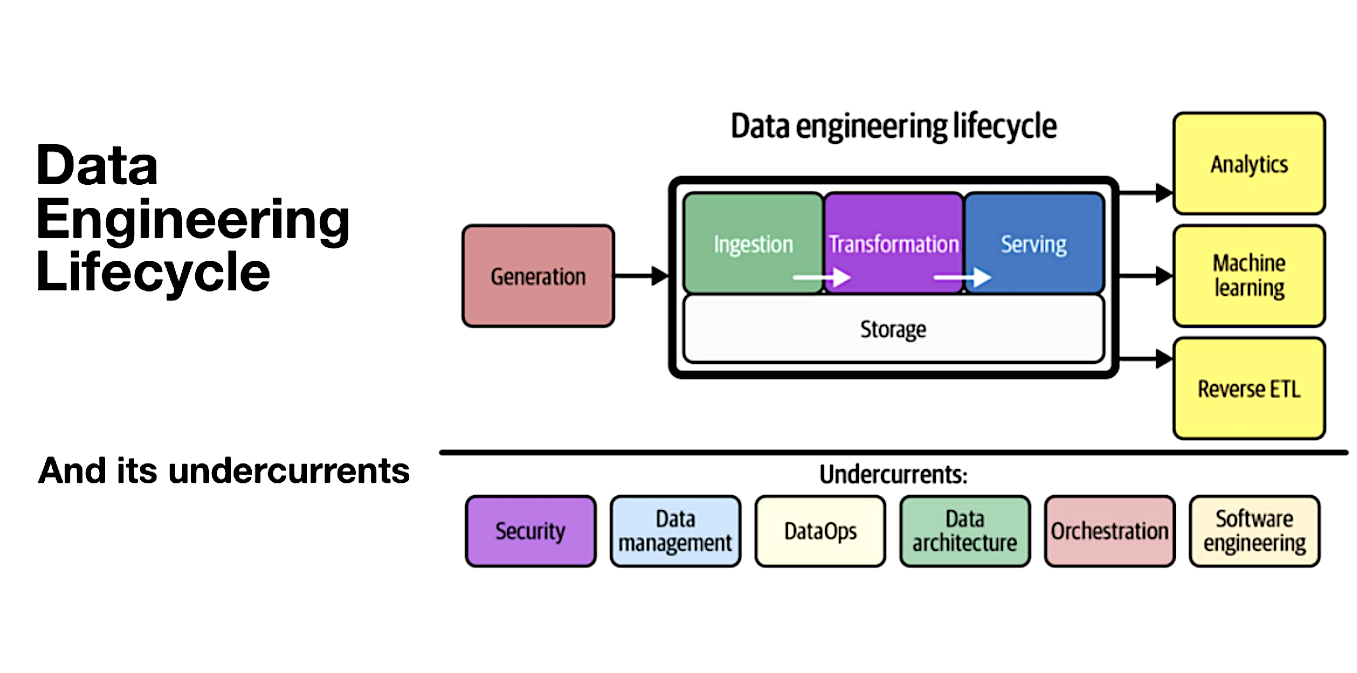
The Data Engineering Lifecycle (Source: Ternary Data)
The authors define the software engineer’s job as owning the lifecycle from data ingestion through transformation and serving (which is the delivery of data in its finished form). There are many decision points at each step of the way, such as whether there is the need to take advantage of an orchestration framework such as Apache Airflow to choreograph the steps in the data pipeline; deciding when, where and how to transform data; and then delivering the data in packaged form to business users.
Reis and Housley also call upon data engineers not simply to be engineers, but to consider themselves in the data business. Specifically, that’s all about acting like an entrepreneur: knowing the customers, knowing their requirements and knowing the core business of the enterprise. This goes far beyond worrying about feeds and speeds and the toolchain. This need to know your customer actually is a good fit for organizations taking data mesh approaches, where data is treated as a product that is managed across its lifecycle. The responsibilities of data engineers in creating and maintaining pipelines and how data is delivered to the customer are a subset of what comprises a data product.
The world has grown a lot more complicated since the on-premises days where interactions with databases were well-defined transactions. To paraphrase Tom Davenport and DJ Patil, though data engineering may no longer be the sexiest job of the 21st century, the authors updated their pronouncement that data science and AI are really a team effort, where data engineers among others play a pivotal role.
Tony Baer is principal at dbInsight LLC, which provides an independent view on the database and analytics technology ecosystem. Baer is an industry expert in extending data management practices, governance and advanced analytics to address the desire of enterprises to generate meaningful value from data-driven transformation. He wrote this article for SiliconANGLE.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





