AI
AI
AI
AI
AI
Meta Platforms Inc.’s Facebook AI Applied Research group today is publicly releasing a new foundational large language model, known as Large Language Model Meta AI or LLaMA, to help the scientific community advance its research into a subset of artificial intelligence known as deep learning.
“LLMs have shown a lot of promise in generating text, having conversations, summarizing written material, and more complicated tasks like solving math theorems or predicting protein structures,” Meta Chief Executive Mark Zuckerberg said on Instagram and Facebook today. “Meta is committed to this open model of research and we’ll make our new model available to the AI research community.”
Large language models are a type of deep learning algorithm that can recognize, summarize, translate, predict and generate text and other content based on knowledge gained from massive datasets. Deep learning uses artificial neural networks to attempt to simulate the behavior of the human brain. Although these neural networks can’t match the ability of the human brain, they can learn from large amounts of data and demonstrating widespread knowledge.
Until now, LLMs have always required extremely powerful computing infrastructure to train and run, making them inaccessible to most researchers. With LLaMA, Meta says it’s democratizing access to LLMs, which are seen as one of the most important and beneficial forms of AI.
The most famous example of an LLM is OpenAI LLC’s GPT-3. The model behind ChatGPT, it has taken the internet by storm thanks to its uncanny ability to respond to almost any kind of question in a humanlike manner. Other kinds of LLMs have been used to solve mathematical problems, predict protein structures for drug development and answer reading comprehension questions. According to Meta, LLMs represent one of the clearest cases of the potential benefits AI can provide to billions of people.
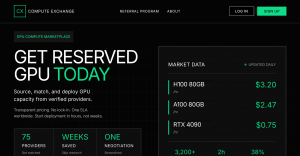
In a blog post, Meta explained that training smaller foundational models like LLaMA is much easier because far less computing power is required to test new approaches, validate other’s work and explore new use cases. Foundational models are typically trained on large sets of unlabeled data, which allows them to be fine-tuned for various different tasks. LLaMA is being made available in several different sizes, ranging from 7 billion to 65 billion parameters.
By making a smaller LLM available to the research community, Meta hopes that researchers will be able to better understand how and why they work, and help to improve their robustness and mitigate problems such as bias, toxicity and their potential for generating misinformation.
Meta explained that LLaMA has another advantage in that it’s trained on more tokens — pieces of words — making it easier to retrain and fine-tune for specific use cases. In the case of the 13 billion-parameter LLaMA, it was trained on 1 trillion tokens. In contrast, GPT-3 was trained on just 300 billion tokens. According to Meta, this makes LLaMA much more versatile, able to be applied to many more use cases than a finely-tuned model like GPT-3, which was designed for more specific tasks.
By sharing the code, Meta added, it’s hoping other researchers can test new approaches to limiting or eliminating issues in large language models. It’s also providing a set of evaluations on benchmarks to evaluate model biases and toxicity.
Meta said that in order to maintain integrity and prevent misuse, LLaMA is being made available under a noncommercial license, meaning it can only be used for research purposes. Access to the model will be granted on a case-by-case basis to academic researchers, to those affiliated with government, civil society and academic organizations, and to industry research laboratories.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.