









 AI
AI
AI
AI
AI
Natural language processing startup Datasaur Inc. said today it has closed on a $4 million seed funding round that brings its total amount raised to date to $7.9 million.
The round was led by Initialized Capital and saw participation from HNVR, Gold House Ventures and TenOneTen. OpenAI LP President Greg Brockman was also named as an early investor in the company.
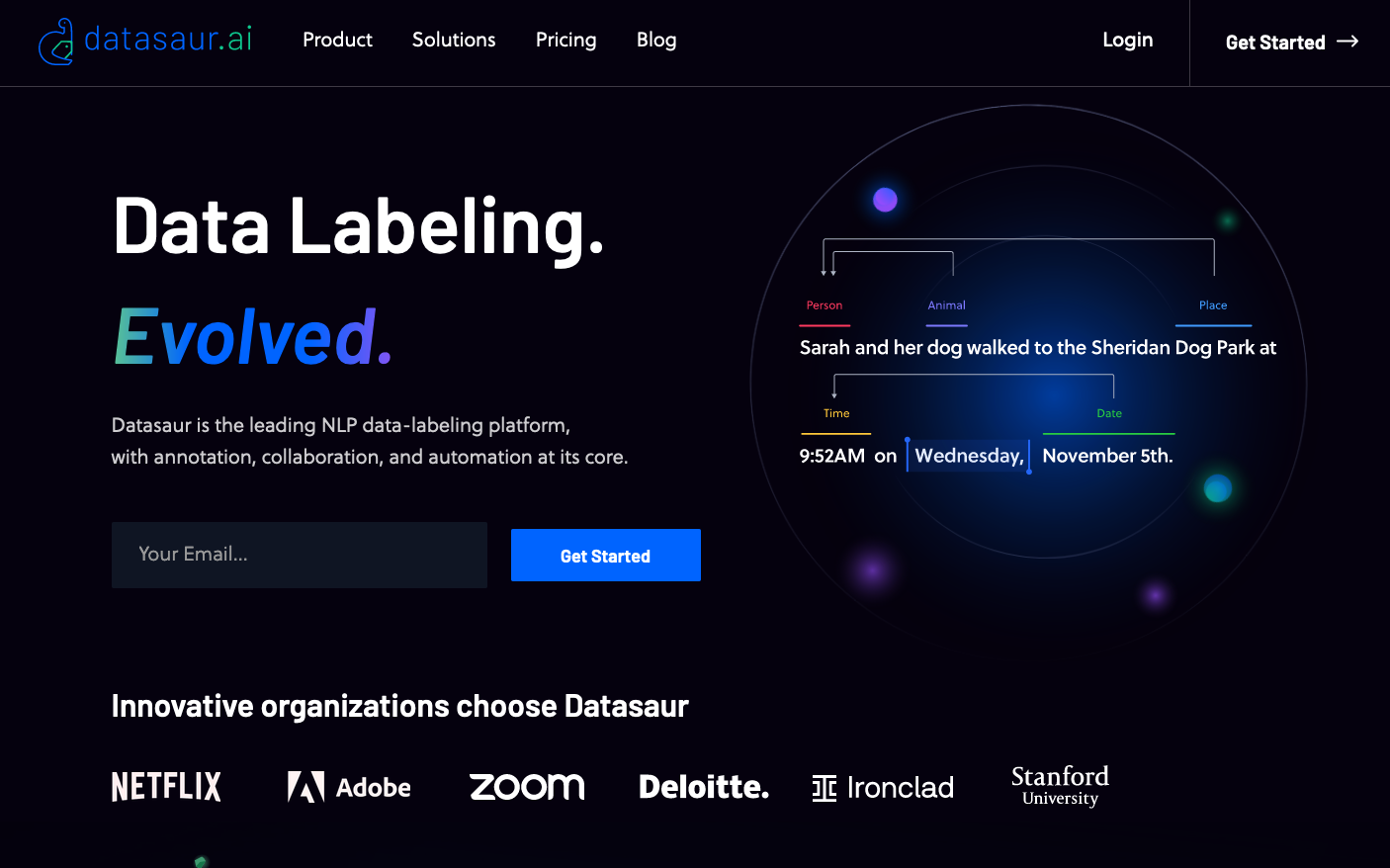
Datasaur is the creator of an intuitive and efficient platform for labeling datasets for natural language processing models. NLP is a subset of artificial intelligence that’s concerned with training computers to understand both spoken words and text in the same way as humans can.
The startup explains that the NLP industry is evolving to a place where companies are increasingly interested in training models on their own proprietary datasets. By doing this, they can train models to handle some very specific tasks in a more efficient way. So companies need an easy way to label their proprietary data and make it ready for AI training.
That’s where Datasaur comes in with its NLP training platform. It enables companies to transform petabytes of raw data into valuable datasets that can be used to train more advanced NLP models. Datasaur said its data labeling tool learns as it carries out its tasks, becoming more accurate and powerful over time. It also provides tools to help companies spot errors in their AI training datasets.
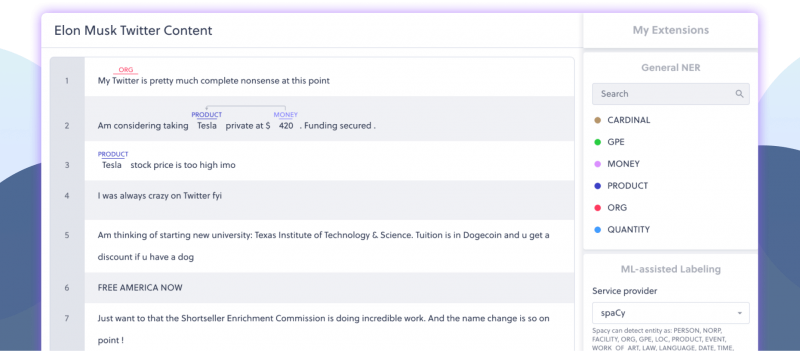
Andy Thurai, vice president and principal analyst of Constellation Research Inc., told SiliconANGLE the importance of having a good data labeling tool cannot be stressed hard enough. He explained that the data used to train generative AI models and large language models like ChatGPT must be carefully annotated in order for them to be trained properly. Poorly labeled data results in inaccuracies, he explained.
“Raw data is about as useless as crude oil is, it needs to be refined with proper labeling and then cleansed for bias, incompletion, anomalies and quality,” Thurai said. “That’s what Datasaur does, using reinforcement learning from human feedback. By keeping humans in the loop, it can improve the efficiency of data annotation.”
The analyst explained that one of the coolest features of Datasaur’s platform is it allows data scientists to add multiple domain experts as annotators, helping to eliminate bias and inaccurate information. “It also provides an option to pre-label or pre-process data, thereby speeding up the annotation process,” he said. “However, the company operates in a very competitive field and there are numerous rival platforms, such as Amazon Mechanical Turk, Appen, SuperAnnotate, DataLoop, V7 Darwin, Cogito, Hive, Edgecase and ClickWorker.”
Perhaps keeping in mind the competitive nature of the data labeling space, Datasaur said today it now wants to become an all-in-one NLP platform. To that end, the company today announced a brand new product called Dinamic, which can transform its customer’s labeled data into a custom NLP model with a single click.
With its data labeling tool and Dinamic, Datasaur says it has transformed a complex, multistep endeavor into a streamlined, two-step process. It allows customers to annotate data based on very specific business requirements and obtain a fully trained NLP model with minimal effort. According to the company, it can save customers “millions of dollars” in data science costs along the way.
Founder and Chief Executive Ivan Lee said the company initially focused on data labeling because it is the most complex and time-consuming step in NLP development. “Today we are in a perfect storm between the dizzying advancements in LLM technology alongside renewed vigor from business stakeholders in translating AI into cost savings and accelerated revenue generation,” he explained.
Datasaur’s biggest claim to fame so far is that its data labeling platform has been used by companies including Google LLC, Qualtrics International Inc. and Spotify Inc. to train both audio clips and text-based data from PDF and Word documents.
Initialized Capital Managing Partner Brett Gibson said the demand for NLP is such that he expects Datasaur’s platform to become much more popular. “We’re seeing companies in every industry and vertical rushing to discover how to apply ChatGPT-like technology to their own processes,” he explained. “Products like Datasaur Dinamic simplify and standardize the process for those new to the NLP space. We saw the potential in the NLP space in 2020 when we first invested in this team, and the time is ripe to capture the rapidly growing market.”
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





