AI
AI
AI
AI
AI
MLCommons, the nonprofit entity for measuring artificial intelligence performance, today announced the results of its MLPerf 4.0 benchmarks for AI inference and other workloads.
With impressive results from both Nvidia Corp.’s and Intel Corp.’s latest chips, the new benchmarks highlight the dramatic pace of evolution in the AI hardware industry.
MLPerf has become the industry gold standard for AI data center benchmarks, which are a series of tests designed to compare the speed of AI-optimized processors as they perform a variety of common tasks. The vendor-neutral results are useful mostly to data center operators, which can use them to guide their purchasing decisions when buying new AI infrastructure.
The benchmarks help show how well various graphics processing units and central processing units perform on a variety of tasks, including inference and training workloads. The MLPerf 4.0 benchmarks saw more than 20 chipmakers participate, with Nvidia and Intel being the main standouts.
MLCommons last published its MLPerf 3.1 results in September 2023, and a lot of new hardware has come onto the market since then, with chipmakers engaged in a race to optimize and improve their silicon chips to accelerate AI. So it’s no surprise that the MLPerf 4.0 results show marked improvements from most participants.
It’s notable that the MLPerf inference benchmark was updated for the latest round of tests. Whereas MLPerf 3.1’s benchmark involved the GPT-J 6B parameter model for text summarization, the newest benchmarks use Meta Platforms Inc.’s open-source Llama 2 70B model as the standard. In addition, MLPerf 4.0 also includes a first-ever benchmark for AI image generation, using Stability AI Ltd.’s Stable Diffusion model.
Nvidia is the most dominant chipmaker in the AI industry and there are good reasons for that, as the latest benchmarks reveal. The company delivered impressive results across the board, showing improvements not only with its latest hardware, but also with some of its existing AI accelerators. For instance, using its TensorRT-LLM open-source inference technology, the company managed to triple the previously-benchmarked performance of its H100 Hopper GPU in text summarization.
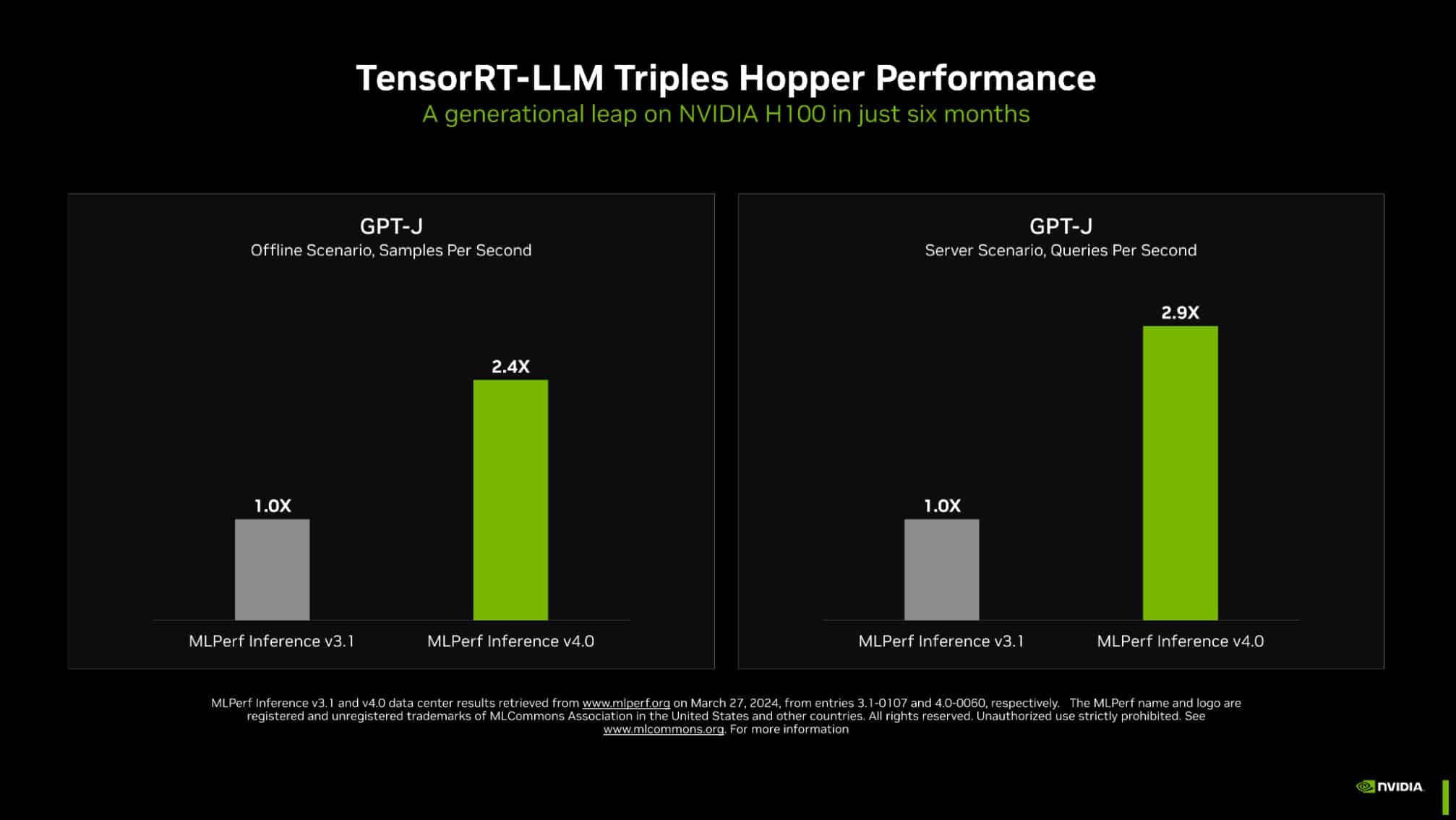
In a media briefing, Nvidia’s director of accelerated computing, Dave Salvator, stressed that the company had managed to triple the performance of the H100 GPU in just six months. “We’re very, very pleased with this result,” he said. “Our engineering team just continues to do great work to find ways to extract more performance from the Hopper architecture.”
Nvidia has not yet benchmarked its most advanced chip, the Blackwell GPU that was announced at its GTC 2024 event just last week, but that processor will almost certainly outperform the H100 chip when it does. Salvator couldn’t say when Nvidia plans to benchmark Blackwell’s performance, but said he hopes it will be able to do so in the near future.
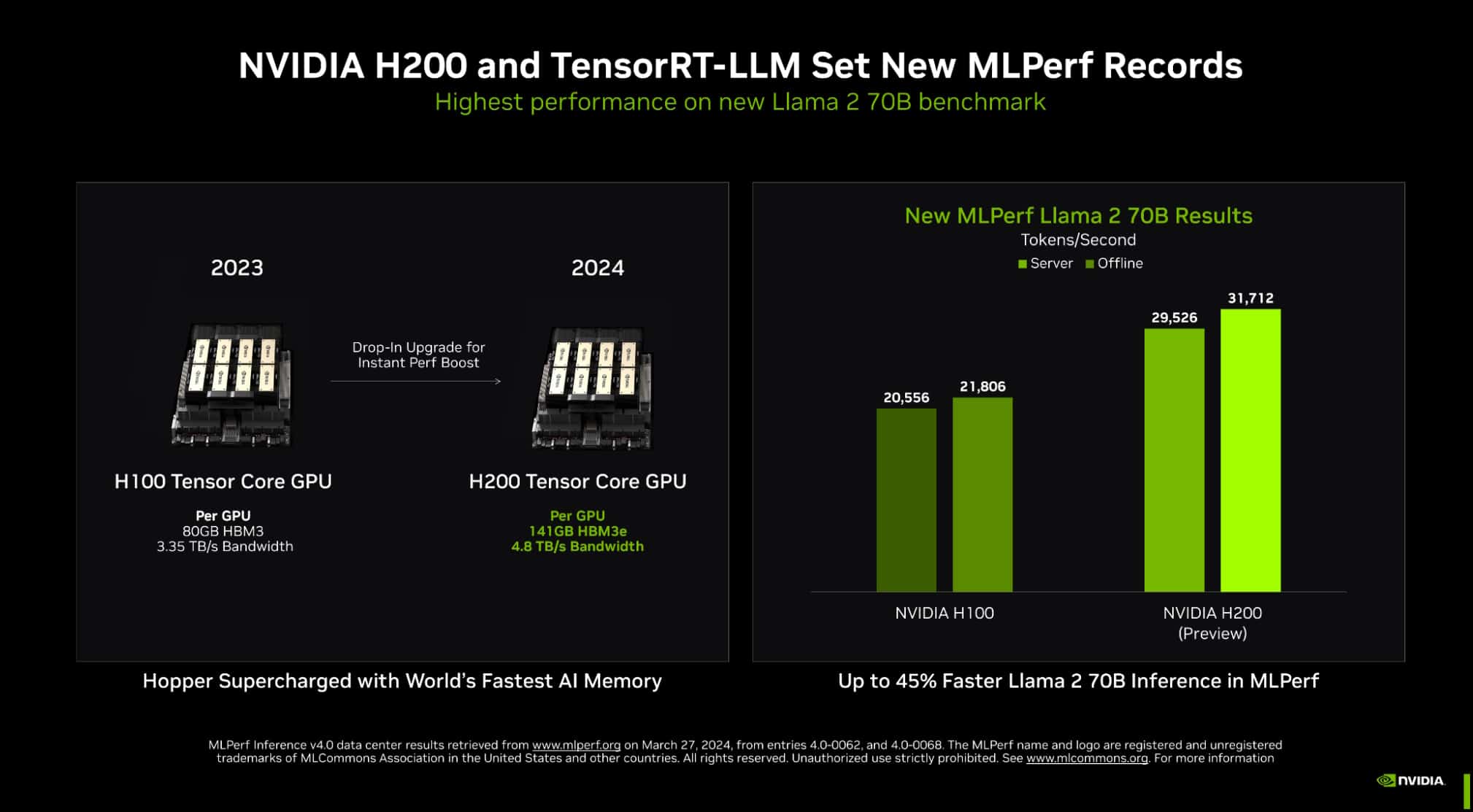
Nvidia did showcase the results of its newer H200 GPU, which is the second-generation of its Grace Hopper architecture-based GPU, and it delivered significant improvements over the H100. For instance, it was rated 45% faster when being tested for inference on Llama 2.
Intel is better known for its CPUs than its GPUs, and that means it has been left behind in an AI industry that places such high value on the latter. However, it does compete in the GPU industry with its Intel Gaudi 2 AI accelerator chip, and the company stressed that it’s currently the only benchmarked alternative to Nvidia’s GPUs.
The chipmaker participated in MLPerf 4.0 with Gaudi and also its Xeon CPU chips, and both showed some impressive gains compared with the previous set of benchmarks. While Gaudi’s overall performance still trails Nvidia’s H100, Intel said the results it actually delivers better price-performance than its rival.

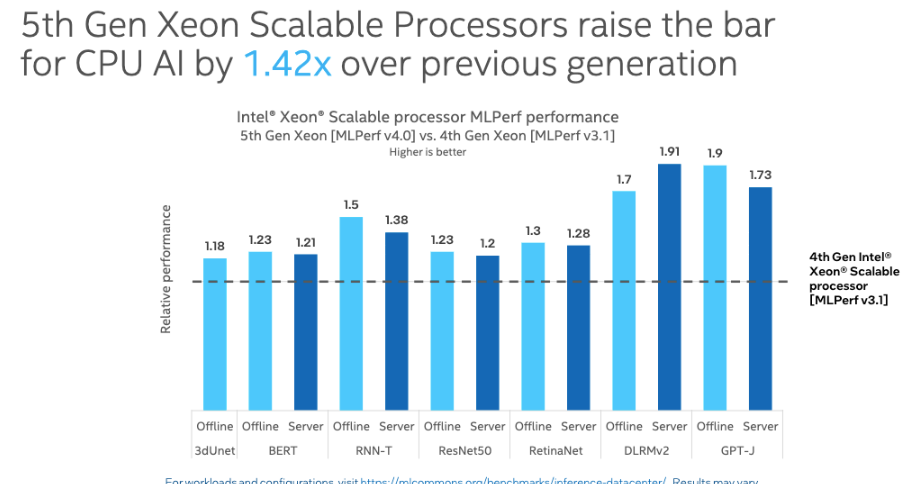
In addition, the 5th Gen Intel Xeon CPU displayed a significant improvement in terms of performance, running 1.4 times faster than the older 4th Gen Intel Xeon CPU in the inference test on Llama 2. In the the GPT-J LLM text summarization benchmark, the latest Xeon chip showed that it was 1.9-times faster than its predecessor.
The results are important, because while the most powerful AI models are trained on GPUs and use those chips for inference, many smaller models are instead being run on CPUs, which are much cheaper and easier to obtain.
Ronak Shah, Intel’s AI product director for Xeon, said the company recognizes that many enterprises are deploying AI applications in “mixed general purpose and AI environments.” As a result, the company has focused its efforts “designing CPUs that mesh together, with strong general purpose capabilities with our AMX engine.”
The latest MLPerf benchmarks provide more than 8,500 results, testing just about every conceivable combination of AI hardware and software applications. According to MLCommons founder and Executive Director David Kanter, the goal is not just to show which type of chip is best in which scenario, but to establish performance metrics that chipmakers can build upon to improve the capabilities of their products. “The whole point is that once we can measure these things, we can start improving them,” he said in a briefing.
In addition, one of MLCommons’ stated goals is to align the chipmaking industry, with each benchmark featuring the same datasets and configuration parameters for different chips and software applications. It’s a standardized approach that enables data center operators to make more informed decisions when it comes to choosing the most appropriate AI architecture for a specific workload.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.