







 AI
AI
AI
AI
AI
Generative artificial intelligence startup AI21 Labs Ltd., a rival to OpenAI, has unveiled what it says is a groundbreaking new AI model called Jamba that goes beyond the traditional transformer-based architecture that underpins the most powerful large language models today.
Announced today, Jamba combines the transformers architecture with Mamba, an older model based on Structured State Space framework. That employs more traditional AI concepts such as neural networks and convolutional neural networks and is more computationally efficient.
The resulting combination is a model that can ingest longer sequences of data, enabling it to handle more context than traditional LLMs, the startup says. Jamba is an acronym of “Joint Attention and Mamba,” and it aims to improve LLMs with support for greater context.
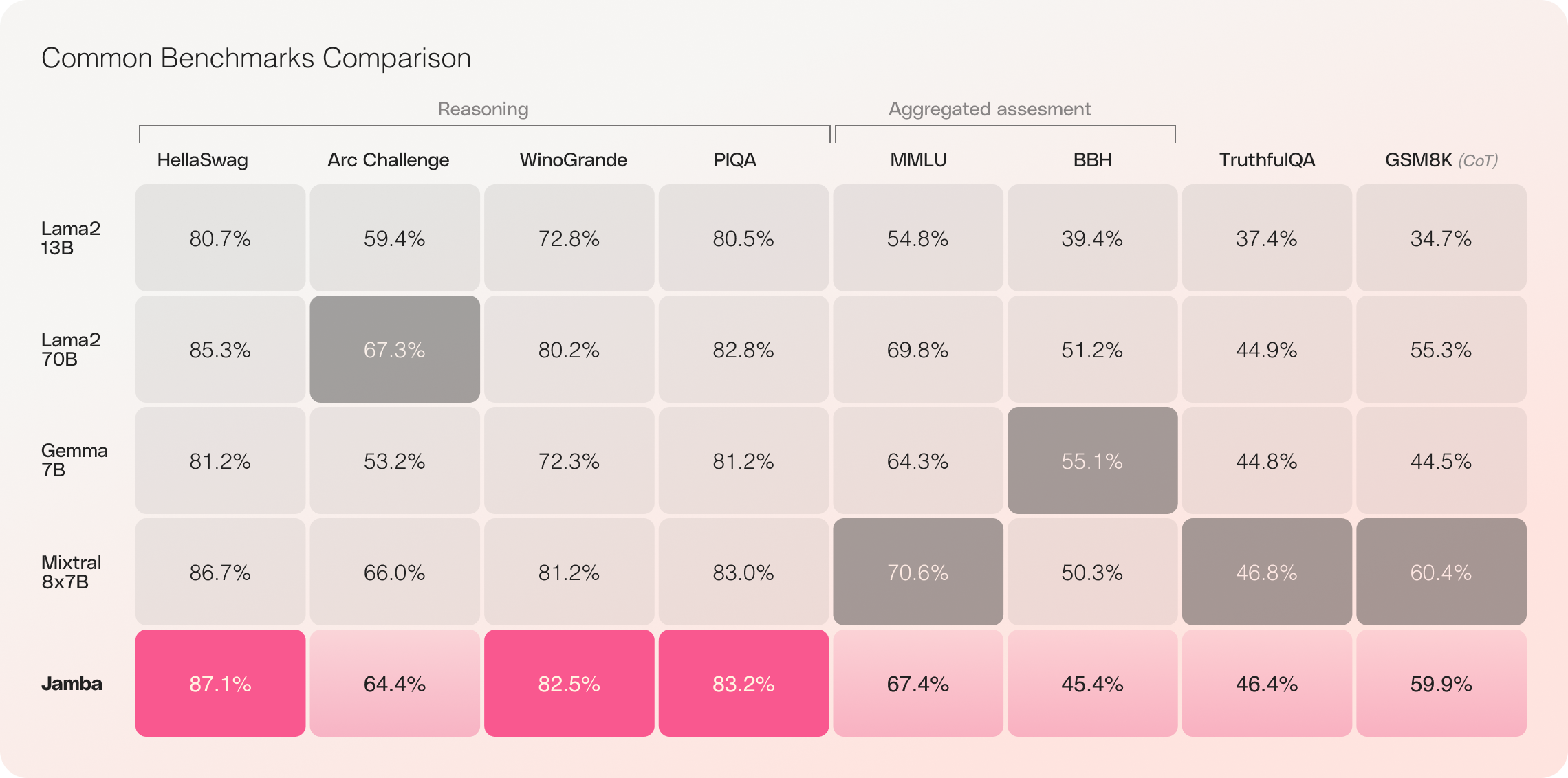
AI21 Labs isn’t trying to replace ransformer models altogether, but it believes that it can supplement them for specific workloads where more context can be helpful. For instance, benchmarks show that Jamba can outperform traditional transformer models on generative reasoning tasks. However, it cannot compete with transformers on other benchmarks, such as the Massive Multitask Language Understanding benchmark that gauges models’ problem-solving abilities.
The Israeli startup says Jamba may prove especially useful in some enterprise scenarios, which is where most of its efforts are focused. The company, which raised $208 million in November, is the creator of tools such as Wordtune, an optimized generative AI model that can generate content in tune with a company’s tone and brand.
Like most of its rivals, AI21 Labs’ previous LLMs have been based on the transformer architecture. These include the Jurassic-2 LLM, which is available through the startup’s natural language processing-as-a-service platform.
The startup said Jamba is not meant to be an evolution of Jurassic-2, but rather something entirely new, a kind of hybrid SSM-transformer model. It’s trying to address some of the shortcomings of transformer LLMs. For instance, transformer models often slow down when the context window grows, as they struggle to process all of the information they need to take in.
The problem with transformers is that their attention mechanisms tend to scale along with sequence length, as each token depends on the entire sequence that preceded it. This ultimately slows down throughput, and is the cause of the low latency responses that affect many LLMs.
In addition, AI21 Labs says, transformers require a much larger memory footprint in order to scale. That makes it difficult for them to run long context windows unless they have access to massive amounts of computing power.
Context is important for AI, because it refers to the input data that a generative AI model considers before generating its response. LLMs with small context windows will often forget the content of their most recent conversations, whereas those with large context windows can avoid that, since they can remember the context of the conversation and adjust their responses accordingly.
Mamba, which was originally developed by Carnegie Mellon and Princeton University researchers, has a lower memory requirement and is equipped with a more efficient attention mechanism, which means it can handle much larger context windows with ease. However, it struggles to match LLMs in terms of pure output and knowledge. As a result, AI21 Labs’ hybrid model is an effort to leverage the strengths of both architectures.

AI21 Labs says Jamba has a remarkable context window of 256,000 tokens, equivalent to about 210 pages of text, and can fit up to 140,000 tokens on a single 80-gigabyte graphics processing unit. That far exceeds most existing LLMs, such as Meta Platforms Inc.’s Llama 2, which manages a 32,000-token context window.
Besides using Mamba, Jamba also integrates what’s known as a “Mixture of Experts” framework to beef up its hybrid SSM/transformer architecture, enabling greater optimization. The model operates on a principle that utilizes MoE layers to draw on just 12 billion of its available 52 billion parameters during inference, allowing for increased efficiency without sacrificing the model’s power or speed.
Jamba is being made available now under an Apache 2.0 license, which has relatively few restrictions with regard to commercial use. That said, the startup warned that it’s not ready to be used commercially just yet, as it doesn’t have any safeguards built in to prevent it from generating toxic outputs. Nor does it have any mitigations against bias, meaning there are risks that its responses might be offensive, inappropriate or inaccurate.
The company does intend to create these safeguards, though, and when it does that, it will offer an enterprise-ready version of Jamba through its platform.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





