







 AI
AI
AI
AI
AI
Open generative artificial intelligence startup Stability AI Ltd., best known for its image generation tool Stable Diffusion, is working hard on developing AI models for 3D video.
Its newest model announced today can take a single video of an object from one angle and reproduce it from multiple angles. Stable Video 4D can transform a video of a 3D object into multiple-angle views of the same object from eight different perspectives. That means it can interpret what the object looks like, including its movements, from the side it cannot see, to allow it to reproduce its movement and appearance from different angles.
The new model builds on the foundation of Stability AI’s Stable Video Diffusion model, which the company released in November. The Stable Video model can take a still image and convert it into a photorealistic video, including motion.
“The Stable Video 4D model takes a video as input and generates multiple novel-view videos from different perspectives,” the company said in the announcement. “This advancement represents a leap in our capabilities, moving from image-based video generation to full 3D dynamic video synthesis.”
This isn’t the first time Stability AI has worked on 3D video. In March the company introduced Stable Video 3D, which cann take images of objects and produce rotating 3D videos of those objects based on the image.
Unlike SV3D, the new Stable Video 4D adds to its capabilities so it can handle an object’s motion. Similar to the SV3D model, SV4D needs to interpret the parts of the object it cannot see to produce the necessary additional perspectives. It also must reproduce invisible motion – such as what might be blocked from view — by understanding the object and its components.
“The key aspects that enabled Stable Video 4D are that we combined the strengths of our previously-released Stable Video Diffusion and Stable Video 3D models, and fine-tuned it with a carefully curated dynamic 3D object dataset,” Varun Jampani, team lead of 3D Research at Stability AI, told VentureBeat in an interview.
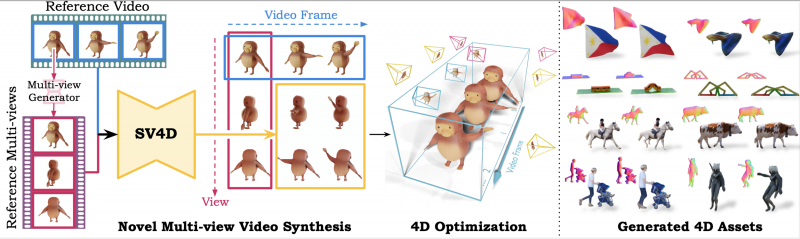
According to the researchers, SV4D is currently capable of generating five-frame videos across eight perspectives in about 40 seconds, with the entire optimization process taking around 20 to 25 minutes. The research team said that using a new approach to multiview diffusion by building on its previous work, it has produced a model that can faithfully reproduce 3D video across both frames and different perspectives.
Although the model is still in the research stages, Stability AI said, SV4D will be a significant innovation for movie production, augmented reality, virtual reality, gaming and other industries where dynamic views of moving objects would be needed.
The model is currently available for developers and researchers to view and use on Hugging Face. It’s the company’s first video-to-video generation model, though it’s still under development as Stability AI continues to refine the model with better optimization to handle a wider range of real-world videos beyond the synthetic datasets it was trained on.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





