







 AI
AI
AI
AI
AI
Meta Platforms Inc. is striving to make its popular open-source large language models more accessible with the release of “quantized” versions of the Llama 3.2 1B and Llama 3B models, designed to run on low-powered devices.
The Llama 3.2 1B and 3B models were announced at Meta’s Connect 2024 event last month. They’re the company’s smallest LLMs so far, designed to address the demand to run generative artificial intelligence on-device and in edge deployments.
Now it’s releasing quantized, or lightweight, versions of those models, which come with a reduced memory footprint and support faster on-device inference, with greater accuracy, the company said. It’s all in the pursuit of portability, Meta said, enabling the Llama 3.2 1B and 3B models to be deployed on resource-constrained devices while maintaining their strong performance.
In a blog post today, Meta’s AI research team explained that, thanks to the limited runtime memory available on mobile devices, it opted to prioritize “short-context applications up to 8K” for the quantized models. Quantization is a technique that can be applied to reduce the size of large language models by modifying the precision of their model weights.
Meta’s researchers said they used two different methods to quantize the Llama 3.2 1B and 3B models, including a technique known as “Quantization-Aware Training with LoRA adaptors,” or QLoRA, which helps to optimize their performance in low-precision environments.
The QLoRA method helps to prioritize accuracy when quantizing LLMs, but in cases where developers would rather put more emphasis on portability at the expense of performance, a second technique, known as SpinQuant, can be used. Using SpinQuant, Meta said it can determine the best possible combination for compression, so as to ensure the model can be ported to the target device while retaining the best possible performance.
Meta noted that inference using both of the quantization techniques is supported in the Llama Stack reference implementation via PyTorch’s ExecuTorch framework.
In its tests, Meta demonstrated that the quantized Llama 3.2 1B and Llama 3B models enable an average reduction in model size of 56% compared to the original formats, resulting in a two- to four-times speedup in terms of inference processing. The company said tests with Android OnePlus 12 smartphones showed that the models reduced memory resource usage by an average of 41%, while almost matching the performance of the full-sized versions.
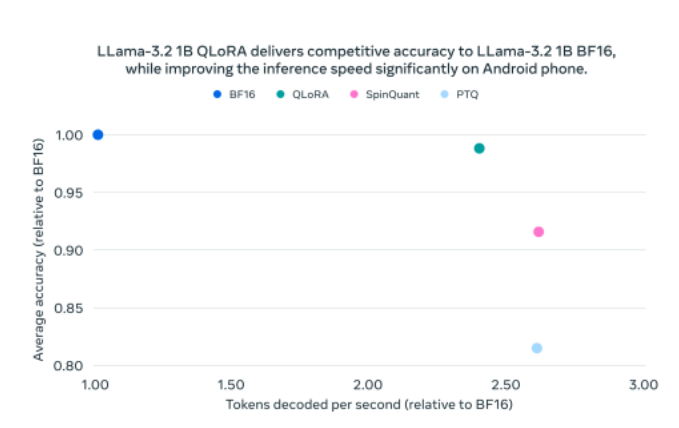
Meta developed the quantized Llama 3.2 1B and Llama 3B models in collaboration with Qualcomm Inc and MediaTek Inc. to ensure that they’re optimized to run on those companies’ Arm-based system-on-chip hardware. It added that it used Kleidi AI kernels to optimize the models for mobile central processing units. By enabling the Llama models to run on mobile CPUs, developers will be able to create more unique AI experiences with greater privacy, with all interactions taking place on the device.
The quantized Llama 3.2 1B and Llama 3B models can be downloaded from Llama.com and Hugging Face starting today.
Meta’s AI research efforts have been in overdrive this month. The quantized Llama models are the company’s fourth major announcement in just the last three weeks. At the start of the month, the company unveiled a family of Meta Movie Gen models that can be used to create and edit video footage with text-based prompts.
A few days later, it announced a host of new generative AI advertising features for marketers, and late last week it debuted an entirely new model called Spirit LM, for creating expressive AI-generated voices that reflect happiness, sadness, anger, surprise and other emotions.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





