





 INFRA
INFRA
INFRA
INFRA
INFRA
Google Cloud is revving up its AI Hypercomputer infrastructure stack for the next generation of artificial intelligence workloads with its most advanced tensor processing unit chipset.
The new Ironwood TPU was announced today at Google Cloud Next 2025, alongside dozens of other hardware and software enhancements designed to accelerate AI training and inference and simplify AI model development.
Google’s AI Hypercomputer is an integrated, cloud-hosted supercomputer platform that’s designed to run the most advanced AI workloads. It’s used by the company to power virtually all of its AI services, including Gemini models and its generative AI assistant and search tools. The company claims that its highly integrated approach allows it to squeeze dramatically higher performance out of almost any large language model, especially its Gemini models, which are optimized to run on the AI Hypercomputer infrastructure.
The driving force of Google’s AI Hypercomputer has always been its TPUs, which are AI accelerators similar to the graphics processing units designed by Nvidia Corp.
Launching later this year, Ironwood will be Google’s seventh-generation TPU, designed specifically for a new generation of more capable AI models, including “AI agents” that can proactively retrieve and generate data and take actions on behalf of their human users, said Amin Vahdat, Google’s vice president and general manager of machine learning, systems and cloud AI. “Only Google Cloud has an AI-optimized platform,” he said in a press briefing Monday.
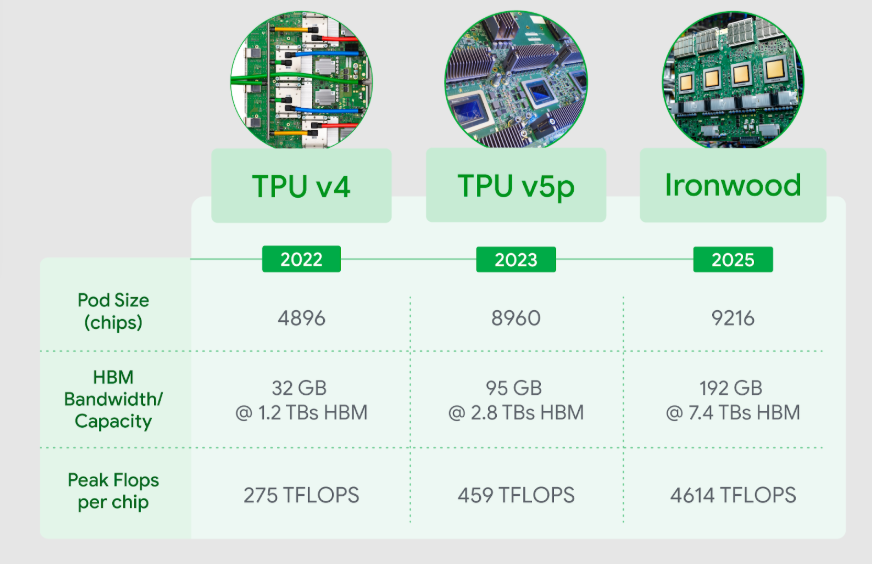
It’s the most powerful TPU accelerator the company has ever built, and it can scale to a megacluster of 9,216 liquid-cooled chips linked together by its advanced Inter-Chip Interconnect technology. In this way, users can combine the power of many thousands of Ironwood TPUs to tackle the most demanding AI workloads.
In a blog post, Vahdat said Ironwood was built specifically to meet the demands of new “thinking models” that use “mixture-of-experts” techniques to perform advanced reasoning. Powering these models requires massive amounts of parallel processing and highly efficient memory access, he explained. Ironwood caters to these needs by minimizing data movement and latency on chip, while performing massive tensor manipulations.

“We designed Ironwood TPUs with a low-latency, high bandwidth ICI network to support coordinated, synchronous communication at full TPU pod scale,” Vahdat said.
Google Cloud customers will be able to choose from two configurations initially, including a 256-chip or 9,216-chip cluster.
When Ironwood is scaled to 9,216 chips, it delivers a total performance of 42.5 exaflops, which is more than 24 times the computing power of El Capitan, officially recognized as the world’s largest supercomputer, at just 1.7 exaflops per pod. Each individual chip provides a peak compute performance of 4,614 teraflops, and they’re supported by a streamlined networking architecture that ensures they always have access to the data they need.
Each Ironwood chip sports 192 gigabytes of high-bandwidth memory, representing a six-times gain on Google’s previous best TPU, the sixth-generation Trillium, paving the way for much faster processing and data transfers. HBM bandwidth also gets a significant boost at 7.2 terabytes per second, per chip, which is 4.5 times faster than Trillium, ensuring rapid data access for memory-intensive workloads.
In addition, Google has introduced an “enhanced” Inter-Chip Interconnect that increases the bidirectional bandwidth to 1.2 Tbps to support 1.5-times faster chip-to-chip communications.
Ironwood also has an enhanced “SparseCore,” or specialized accelerator that allows it to process the ultra-large embeddings found in advanced ranking and recommendation workloads, making it ideal for real-time financial and scientific applications, Vahdat said.
For the most powerful AI applications, customers will be able to leverage Google’s Pathways runtime software to dramatically increase the size of their AI compute clusters. With Pathways, customers aren’t limited to a single Ironwood pod, but can instead create enormous clusters spanning “hundreds of thousands” of Ironwood TPUs.
Vahdat said these improvements enable Ironwood to deliver twice the overall performance per watt compared with the sixth-generation TPU Trillium, and a 30-times gain over its first-generation TPU from 2018.
Ironwood is the most significant upgrade in the AI Hypercomputer stack, but it’s far from the only thing that’s new. In fact, almost every aspect of its infrastructure has been improved, said Mark Lohmeyer, vice president of compute and AI infrastructure at Google Cloud.
Besides Ironwood, customers will also be able to access a selection of Nvidia’s most advanced AI accelerators, including its B200 and GB200 NVL72 GPUs, which are based on that company’s latest-generation Blackwell architecture. Customers will be able to create enormous clusters of those GPUs in various configurations, utilizing Google’s new 400G Cloud Interconnect and Cross-Cloud Interconnect networking technologies, which provide up to four times more bandwidth than its predecessor, the 100G Cloud Interconnect and Cross-Cloud Interconnect.
Other new hardware improvements include higher-performance block storage, and a new Cloud Storage zonal bucket that makes it possible to colocate TPU and GPU-based clusters to optimize performance.
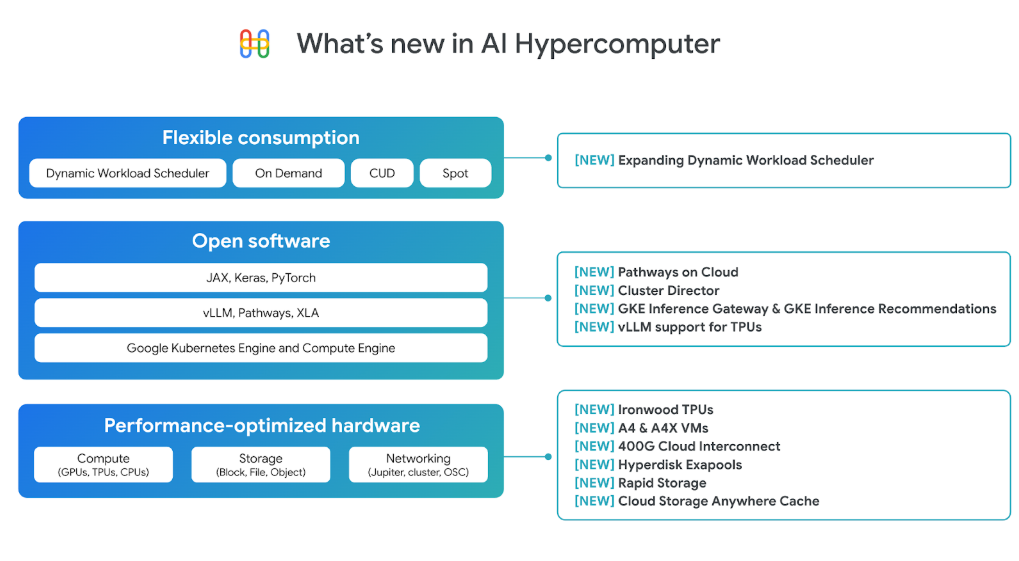
Lohmeyer also discussed a range of software updates that he said will enable developers and engineers to take full advantage of this speedier, more performant AI architecture.
For instance, the Pathways runtime gets new features such as disaggregated serving to support more dynamic and elastic scaling of inference and training workloads. The updated Cluster Director for Google Kubernetes Engine tool, formerly known as Hypercompute Cluster, will make it possible for developers to deploy and manage groups of TPU or GPU clusters as a single unit with physically colocated virtual machines to support targeted workload placement and further performance optimizations. Cluster Director for Slurm, meanwhile, is a new tool for simplified provisioning and operating Slurm clusters with blueprints for common AI workloads.
Moreover, observability is being improved with newly designed dashboards that provide an overview of cluster utilization, health and performance, plus features such as AI Health Predictor and Straggler Detection for detecting and solving problems at the individual node level.
Finally, Lohmeyer talked about some of the expanded inference capabilities in AI Hypercomputer that are designed to support AI reasoning. Available in preview now, they include the new Inference Gateway in Google Kubernetes Engine, which is designed to simplify infrastructure management by automating request scheduling and routing tasks. According to Google, this can help to reduce model serving costs by up to 30%, tail latency by 60%, and increased throughput of 40%.
There’s also a new GKE Inference Recommendations tool, which simplifies the initial setup in AI Hypercomputer. Users simply choose their underlying AI model and specify the performance level they need, and Gemini Cloud Assist will automatically configure the most suitable infrastructure, accelerators and Kubernetes resources to achieve that.
Other capabilities include support for the highly optimized inference engine vLLM on TPUs, plus an updated Dynamic Workload Scheduler that helps customers get affordable access to TPUs and other AI accelerators on an on-demand basis. The Dynamic Workload Scheduler now supports additional virtual machines including TPU v5e, which is powered by Google’s Trillium TPUs, A3 Ultra, powered by the Nvidia H200 GPUs, and A4, powered by Nvidia’s B200 GPUs.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





