

















 AI
AI
AI
AI
AI
Starburst Data Inc., provider of a unified data access platform based on the open-source Trino distributed query engine, today is unveiling a suite of enhancements intended to make it easier for enterprises to develop and apply artificial intelligence models.
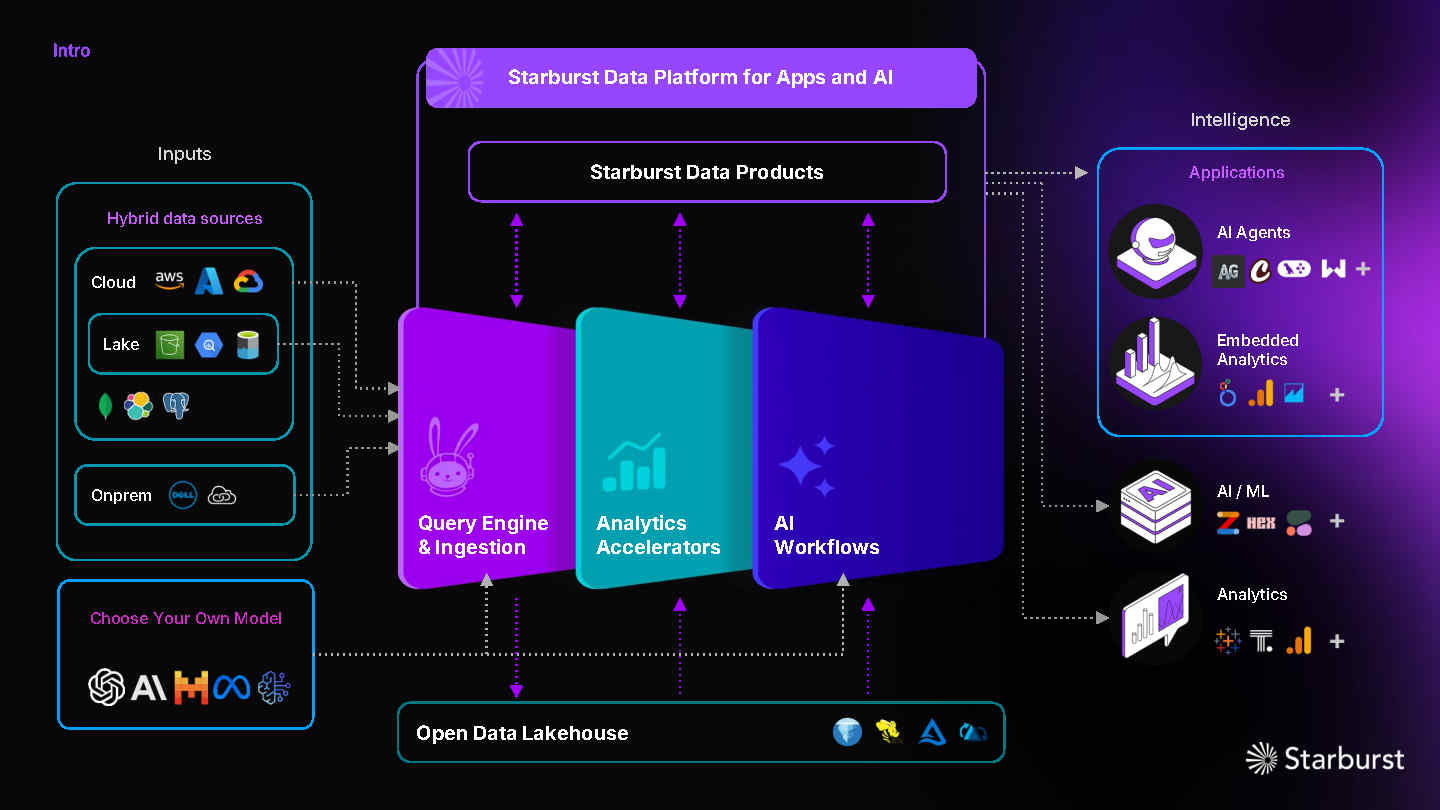
The company is making it easier by simplifying access to data scattered across clouds, on-premises systems and hybrid environments. The announcements center on new capabilities in Starburst’s Enterprise Platform and Galaxy managed offerings that address the complexity of accessing and managing large volumes of distributed data.
Starburst positions itself as an enabler of enterprise AI for companies with complex, distributed and sensitive data who don’t want to adopt new infrastructure or migrate massive datasets. The company is focused on tools that bring AI capabilities to data.
“Our core differentiator is around data access, bringing what you need into the lakehouse for high performance and scalability,” said Nick Kessler, AI product marketing leader at Starburst.
Starburst’s updates are focused on enabling what it calls an AI “lakeside,” in which companies can use data where it already lives without needing to copy it into a centralized repository. Starburst defines a lakeside as a staging ground for AI, or an area adjacent to the data lakehouse where data is the most complete, cost-efficient and governed.
The company’s new Lakeside AI architecture combines AI-ready tools with an open data lakehouse model. It allows companies to experiment with, train and deploy AI systems while keeping sensitive or regulated data in place.
Starburst AI Workflows accelerates AI application development by making it easier to transform unstructured data into vector embeddings, a machine learning technique that turns data into numerical representations that capture the meaning and relationships between different data points without requiring explicit keywords.
Workflows manage prompts and models with SQL and enforce governance policies. Starburst said these capabilities are fully contained within its platform and require no external data pipelines. Data is stored on Apache Iceberg tables with connectors available for a variety of third-party vector databases.
Basically, this means users can build AI features that rely on unstructured or semi-structured sources like emails, documents and logs without having to move data or stitch together multiple tools.
The Starburst AI Agent is a built-in natural language interface that allows users to talk to their data using natural language. They can ask questions like, “What were our sales in Europe last quarter?” and the AI agent will identify relevant data and generate SQL queries behind the scenes.
“It’s agentic in that it’s not just a wrapper around the large language model but focused on natural language conversation,” said Matt Fuller, vice president of AI/ML products at Starburst. “You can see what it’s doing behind the scenes.”
The AI Agent is designed to operate securely in the air-gapped or highly regulated environments common to healthcare, government or finance. Future plans include adding support for the Model Context Protocol and Agent2Agent protocol for connecting agents.
Starburst is addressing one of the most time-consuming tasks in AI projects with an AI-powered auto-tagging feature in Galaxy. It automatically scans for sensitive data such as names, email addresses and other personally identifiable information at the column level and tags it so access policies can be applied. That reduces the need for manual checks and helps organizations enforce privacy rules more consistently.
A new Starburst data catalog replaces the aging Hive metastore and provides better support for the Iceberg data format that is rapidly becoming the standard for cloud data lakes. The new catalog supports both legacy Hive data and Iceberg tables.
“Hive doesn’t speak modern protocols and there are a lot of vulnerabilities in the software itself; this is a modernized replacement with Iceberg-native features,” said Matt Fuller, vice president of AI/ML products. “You can still access your old data in Hive and [Amazon Web Services Inc.’s] Glue. If you already have a catalog we’ll be compatible with it.”
Fully managed Iceberg pipelines now allow for automated table maintenance, including file cleanup and compaction, along with options for streaming or batch data ingestion.
To improve performance across large-scale deployments, Starburst is also introducing a native ODBC Driver that improves connection speed and reliability with business intelligence tools such as Salesforce Inc.’s Tableau and Microsoft Corp.’s Power BI.
Role-based query routing routes queries to the right compute cluster based on a user’s role, improving speed and optimizing costs. Deployment set routing spreads queries across multiple clusters to handle spikes in demand and ensure resilience.
Starburst also revealed a strategic investment from Citigroup Inc., a move it said burnishes its reputation in highly regulated sectors. Citi is using Starburst to unify data access across 165 countries while maintaining data sovereignty.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





