AI
AI
AI
AI
AI
Beijing, China-based Meituan Inc. today debuted its next-generation LongCat-2.0 open-source large language model, stating that the company trained the 1.6-trillion-parameter model on domestic Chinese chips and compute clusters.
The larger takeaway for this colossal model isn’t just the open-source release, it’s the domestic hardware throughline.
Meituan may initially seem like an unlikely place for AI models to come from. Often described as China’s answer to DoorDash, the company started as the country’s dominant food delivery platform but evolved into a combination of services that include travel and leisure booking, discovery and rating of local businesses and ride-hailing.
The company jumped into the AI model development scene as far back as 2023 when it acquired the startup Light Year Beyond for $281 million, but did not announce its own internal plans to develop an AI model until 2025.
At a high level, LongCat-2.0 follows a similar sparse mixture-of-experts model as Mistral AI’s Mixtral and DeepSeek. It uses an internal router architecture that selects a curated set of “expert AIs” per token rather than lighting up the entire model at once. This provides core efficiency for model deployment and inference, allowing MoE models to scale on cheaper hardware without needing to deploy the entire model to compute every token.
Weighing in at 1.6 trillion parameters, the model is no lightweight and it delivers with a 1 million-token context window. This means that users can input tremendous amounts of data at once. By way of comparison, it sits alongside MoE models such as DeepSeek-R1-0528 and OpenAI Group PBC’s open-source GPT-OSS, which emphasize smaller activation footprints and industry-standard 128,000-token context windows, whereas LongCat-2.0 focuses on being very heavy and providing long context.
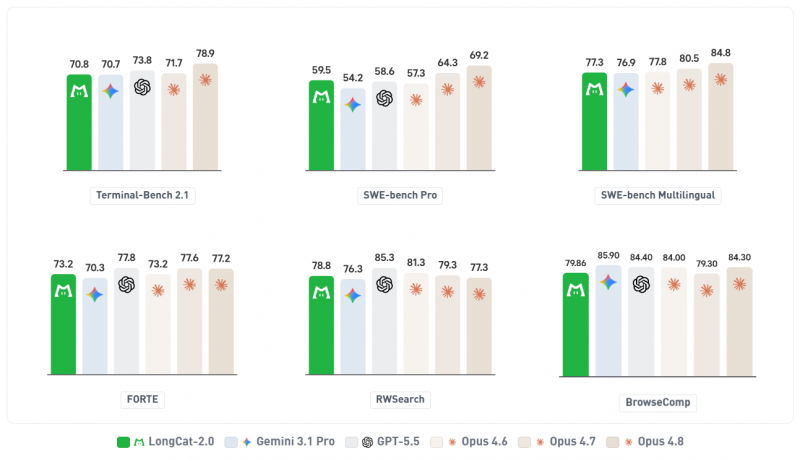
The company has released benchmarks for the model pace it with ultra-powerful closed-source industry models such as Google LLC’s Gemini, OpenAI’s GPT-5.5 and Anthropic PBC’s Claude Opus. The company said it designed LongCat-2.0 to work as a “brain,” or the core, of AI agents and coding harnesses such as Claude Code, OpenClaw and Hermes.
Meituan said the model delivers strong performance for code understanding, repository-level edits, automated task execution and agentic workflows. The objective is to provide developers with a stable and efficient tool that uses a model to orchestrate long-term goals and task management.
According to the company, the new model was both trained and optimized for domestic AI Application-Specific Integrated Circuit clusters, a position that is required because China has been intermittently choked off from access to Nvidia Corp.’s most powerful CUDA-based graphics processing units and chipsets.
Although Nvidia chips can currently flow to China, the turbulence caused by export controls has prompted the country to seek alternatives. According to a report from Bernstein, a global equity research and brokerage firm, it was estimated in 2025 that Nvidia held around 40% of the market share in China for AI chips, roughly matched by Huawei Technologies Co., Ltd. Bernstein predicted Nvidia’s market share will fall by 8% this year, giving Huawei room to grow.
The model’s training origin means it will run reliably and likely perform well on domestically available chips in China, while reducing dependence on Nvidia-specific software and its market dominance. The company said it was trained on ASIC “superpods,” which suggests enterprise deployment within the same ecosystem and not on third-party hardware.
At 1.6 trillion parameters, LongCat-2.0 will not be showing up for consumer hardware anytime soon, and it’s unlikely to run on-premises for most enterprise workloads. At that size, it will live in a data center or cloud environment, where it can be distributed across high-density inference clusters under management, with model parallelism. If it really is architected the way Meituan claims, then its core reasoning is portable to other hardware, but the performance optimizations will remain on domestic chips.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.