





















 APPS
APPS
APPS
APPS
APPS
Google LLC is refusing to let up on the artificial intelligence front. In its latest update, the web giant today announced some major changes to its popular Cloud Speech Application Programming Interface, which was first introduced in 2016.
Google said it’s renaming the Cloud Speech API as “Cloud Speech-to-Text” in a move that helps identify it as an actual service rather than a tool for developers to play with. The service itself has also gained a number of new enhancements that should help to improve its reliability as a transcription aid for enterprises and other users.
The announcements were made in a blog post by Google Cloud AI Product Manager Dan Aharon, who said much of the focus was on boosting Cloud Speech-to-Text’s phone and video call transcription capabilities. To do this, Aharon and his team have introduced new models specifically for these mediums. Users can now select the most appropriate model for each situation, whereas previously the API would do this automatically.
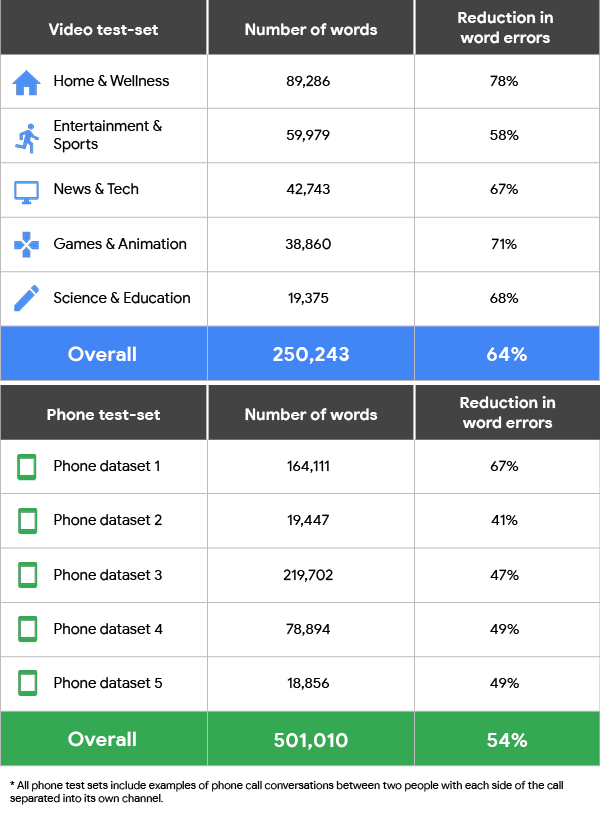
The enhanced “phone_call model” was notably built with privacy in mind, meaning that the set of thousands of hours of training data used in its creation was provided voluntarily by Google’s enterprise customers. Google reckons the new model ensures 54 percent less errors when transcribing phone conversations than its previous basic phone_call model.
There’s also a new model for video call situations that’s based on machine learning technology used by YouTube to provide subtitles for its videos. In this case, Google claims a 64 percent reduction in errors compared with its earlier model.
Both the enhanced phone_call and premium-priced video model are now available for U.S. English transcription, and they will soon be available for additional languages, Aharon said. “We also continue to offer our existing models for voice command_and_search, as well as our default model for longform transcription.”
Google is offering a free demo of Cloud Speech-to-Text’s new models here.
In addition to the improved models, Cloud Speech-to-Text now can handle punctuation for the first time, albeit in beta only. As Aharon conceded in his post, “properly punctuating transcribed speech is hard to do,” but the company believes it has cracked the problem by creating something called a long short-term memory neural network that adds commas, periods and question marks to run-on sentences.
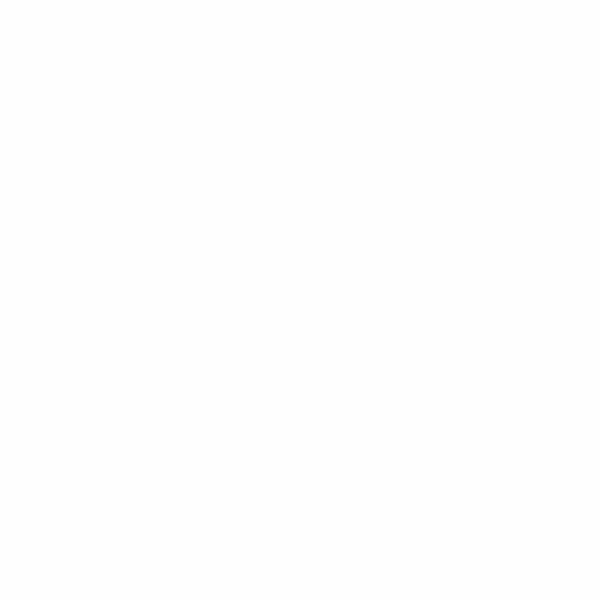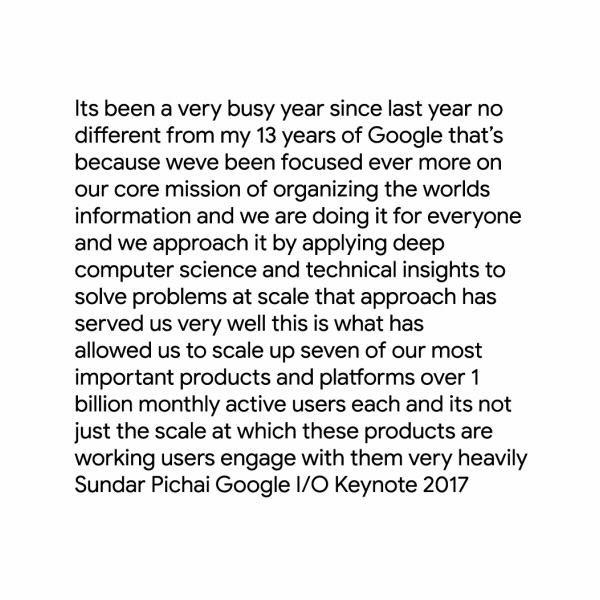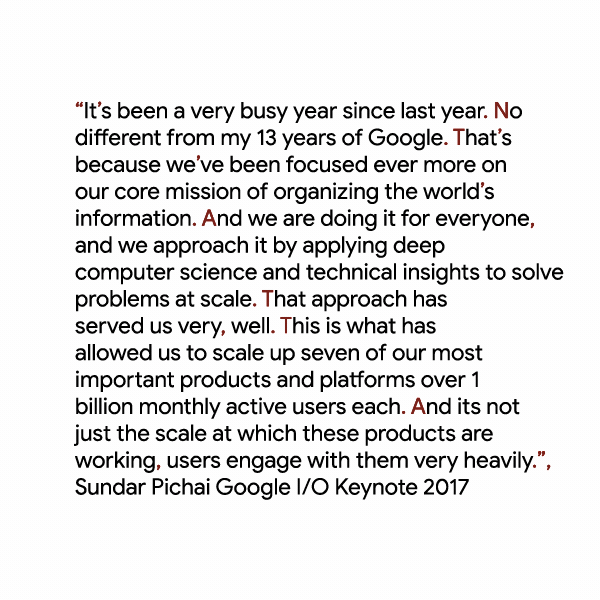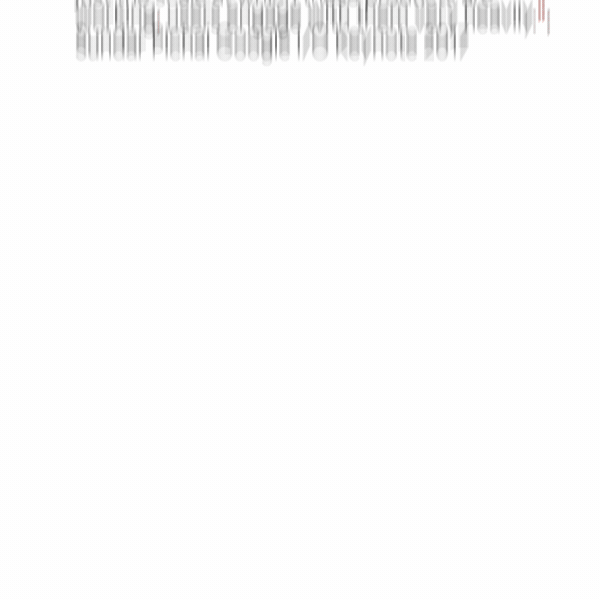
Finally, Google is hoping its users will help improve Cloud Speech-to-Text by providing recognition metadata to transcribed audio and video. The idea is that users will be able to tag audio and video recordings according to the kind of content they contain. Examples of tags might be “voice commands for a shopping app” or “basketball sports TV shows.” This data will then be aggregated across users to inform Google on what its main focus for future updates should be.
Google said Cloud Speech-to-Text is available now priced at six-tenths of a cent per 15 seconds for all models, except for the video model, which is twice as expensive at 1.2 cents per 15 seconds.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





